

Big Data freaks me out. Chalk it up to being spoonfed George Orwell at an early age or adolescent heroes like Fox Mulder and Neo, but I still do not trust institutions that want my information.
On the other hand, I use Google for everything, Alexa lives in more rooms than I care to admit, and I still expect Netflix to remember what I watched years ago. We live inside this dichotomy of acceptable spying and unacceptable spying.
Cyberstalking acquaintances, colleagues, and future partners has become casual conversation. As consumers, we like being shown the exact thing we do not really need the minute we pop around to a friendly internet megastore. As employees, that same collection and prediction can feel very different. That is the tension people analytics has to live inside: data can make work better, but only if people are not reduced to raw material for a model.
Big Data already shapes customer profiles, education, healthcare, finance, and the way companies make decisions. Human Resources was traditionally more art than science, but people analytics, HR analytics, workforce analytics, and talent analytics now give HR teams a harder data layer for hiring, retention, engagement, performance, and workforce planning.
In addition to customer profiles, education, healthcare, and finance all rely on Big Data. HR departments used to rely more heavily on instinct, interviews, and manager memory. Now people analytics lets HR teams apply hard data to questions that used to be answered through gut feel.
In this Process Street post, we will look at what Big Data means and the three primary ways it influences the hows, whys, and whats of people analytics.
- What exactly is Big Data?
- The 4 V’s of Big Data
- The future of Big Data and people analytics
- Prediction is very difficult, especially if it’s about the future.
To the future.
What exactly is Big Data?

The definition of Big Data is nebulous at best. Conventionally, Big Data means large, complex data sets that are extremely difficult or impossible to process with ordinary tools.
The problem is the phrase large, complex data set. What qualifies as large and complex changes quickly. A phone storage tier that felt impossible in 2007 now looks ordinary. The same thing happens inside companies: yesterday’s overwhelming data set becomes today’s baseline operating data.
In 2001, Gartner analyst Doug Laney introduced the 3 V’s of Big Data: volume, velocity, and variety. Gartner’s definition, later summarized in Forbes, is still useful because it avoids treating Big Data as just a synonym for a lot of data.
Jean-Paul Isson and Jesse S. Harriott’s People Analytics in the Era of Big Data adds the part HR teams care about most: data has to change how you attract, acquire, develop, and retain talent. Otherwise it is just expensive noise.
Isson has worked as an analytics consultant, speaker, author, and advisor. Harriott has worked as a chief analytics officer and people analytics leader. Their examples still matter because they connect data collection to actual HR decisions instead of treating analytics as a novelty.
People analytics uses employee and workforce data to make better decisions about people. Big Data expands the inputs: recruiting funnels, onboarding completion, engagement surveys, collaboration patterns, learning history, performance signals, retention risk, workforce plans, and the operational steps that show whether a people process actually happened.
The 4 V’s of Big Data
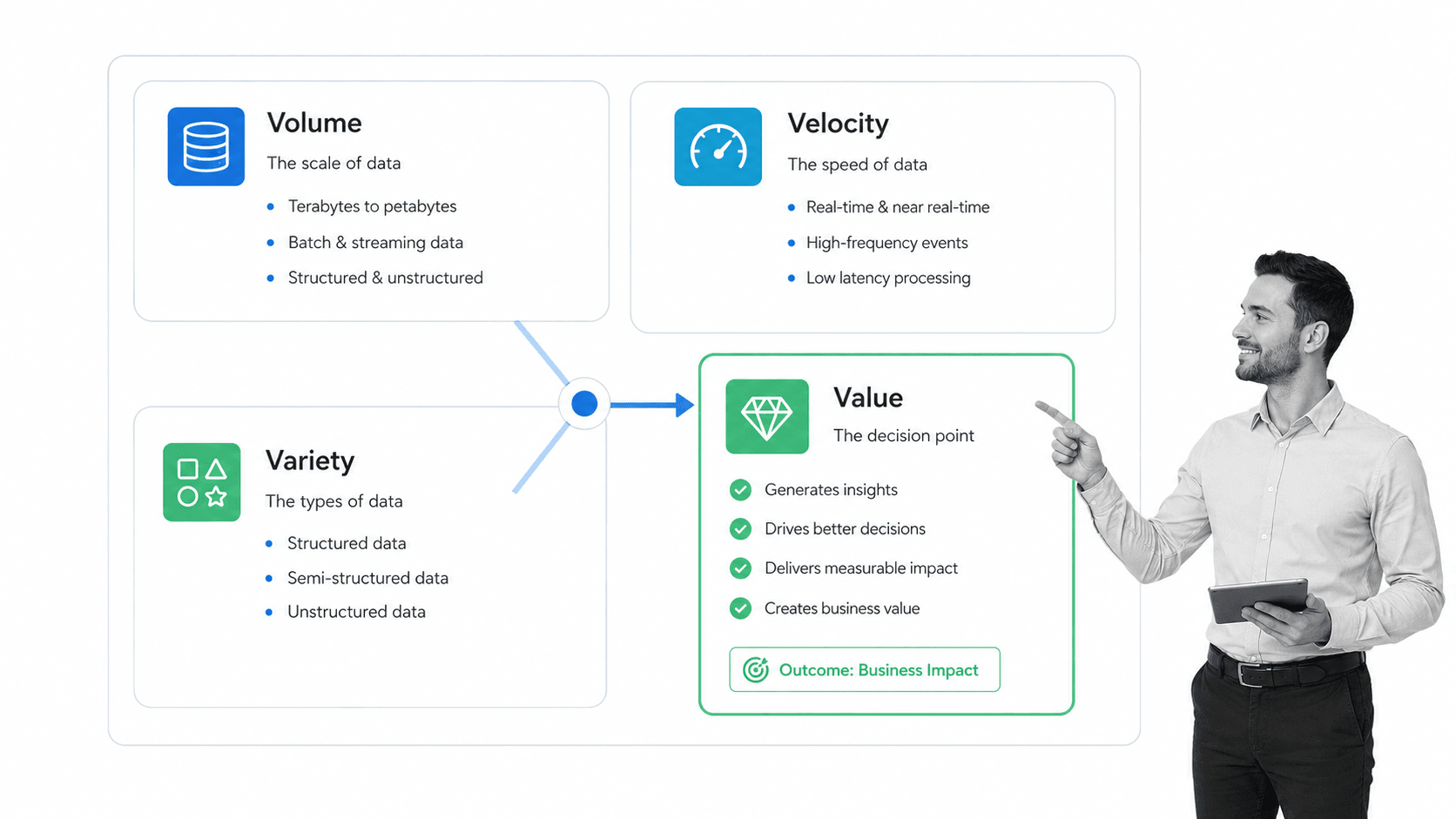
The original 3 V’s still do most of the work, but people analytics needs a fourth: value. The data is not useful because it is big. It is useful when it leads to better decisions and better work.
Volume
Volume is the amount of data available. As Isson and Harriott put it, the exact criteria for what is considered large volume is a moving target because technology improves so rapidly that yesterday’s large-volume data set becomes today’s typical-size data set.
The advantage of more volume is that statistical models can make more accurate behavior predictions when the inputs are relevant and clean. Best informed is best prepared, after all.
That said, large volumes of employee data can be unwieldy. Organizations may have the ability to store archived data, but lack the structure, governance, and workflow discipline to do anything useful with it.
Velocity
Velocity means Big Data travels very fast and does not stop. The modern company needs the architecture and tools to process very fast, very large data coming in nonstop without turning HR into a permanent reporting backlog.
For people analytics, velocity matters when a change needs action now: a spike in attrition risk, a stalled onboarding cohort, a sudden engagement drop, or a hiring bottleneck that will damage next quarter’s plan if nobody catches it. It is the same general principle behind Amazon recommending related items at checkout or a grocery store reminding you about a frequently bought item, only the stakes are higher when the subject is an employee.
Variety
Customer comments on social media, popular search terms on Google, GPS or WiFi tracking, metadata on uploaded images and videos, survey responses, support tickets, workflow history, and collaboration patterns can all become inputs. The sources and channels used to retrieve Big Data keep expanding.
The challenge is that companies receive unstructured data alongside traditional structured data. Without the right infrastructure to review it, unstructured data remains useless. The advantage, though, is that this variety can create a more complete view of an individual’s actions and motivations, which allows for more accurate and precise algorithms to develop.
Value
I hoard information pretty indiscriminately. My partner is always asking: What are you going to do with that information? And I invariably respond: I do not know, but I have it.
I would estimate that a good 85 to 90 percent of the knowledge I have is random detritus I picked up somewhere. No, it does not make me exceptionally good at pub quizzes. Sometimes that data is unexpectedly useful, but more often than not, like all the other things we hold onto because we might need them in the future, it sits there gathering figurative dust in my brain.
That is a terrible data strategy. Big Data without business value is simply noise. Volume, velocity, and variety bring the picture into focus. Value is about what you can do with that picture.
For HR, value might mean identifying why high performers leave, spotting onboarding friction before a new hire churns, understanding which teams need support, or finding the point where a performance process creates more anxiety than clarity.
The book points to examples such as SITA, the aviation industry IT provider, using analytics to understand and improve workforce planning, and Workhuman, now positioned around Workhuman iQ, using employee recognition data to surface actual sentiments and relationship patterns. The point is not that every company needs those exact tools. The point is that value begins when data changes a people decision.
The future of Big Data and people analytics
Back in the olden days, job hunters had to physically hand in their CVs in person. If they looked like a good match on paper, they got an interview and the hiring manager asked questions like, What is your biggest weakness?
That world did not disappear completely, but people analytics has changed the center of gravity. Hiring, onboarding, engagement, retention, and workforce planning now depend on systems that collect signals before a manager ever opens a spreadsheet.
Cyborg HR: Resistance is futile
We are a society of cyborgs. Modern science fiction taught us to imagine cyborgs as organic beings permanently fused with machines: the Terminator, Star Trek’s Borg Collective, RoboCop. That is only one idea of the cyborg, though.
From implants and artificial organs to cell phones and smart homes, humans and machines are already mixed into ordinary life. HR is no different. The more work becomes digital, the more people analytics depends on machine-collected signals.
We know from experience that the amount of data being captured has increased exponentially, even just in recent years, and shows absolutely zero signs of slowing down. It is a simple question of supply and demand.
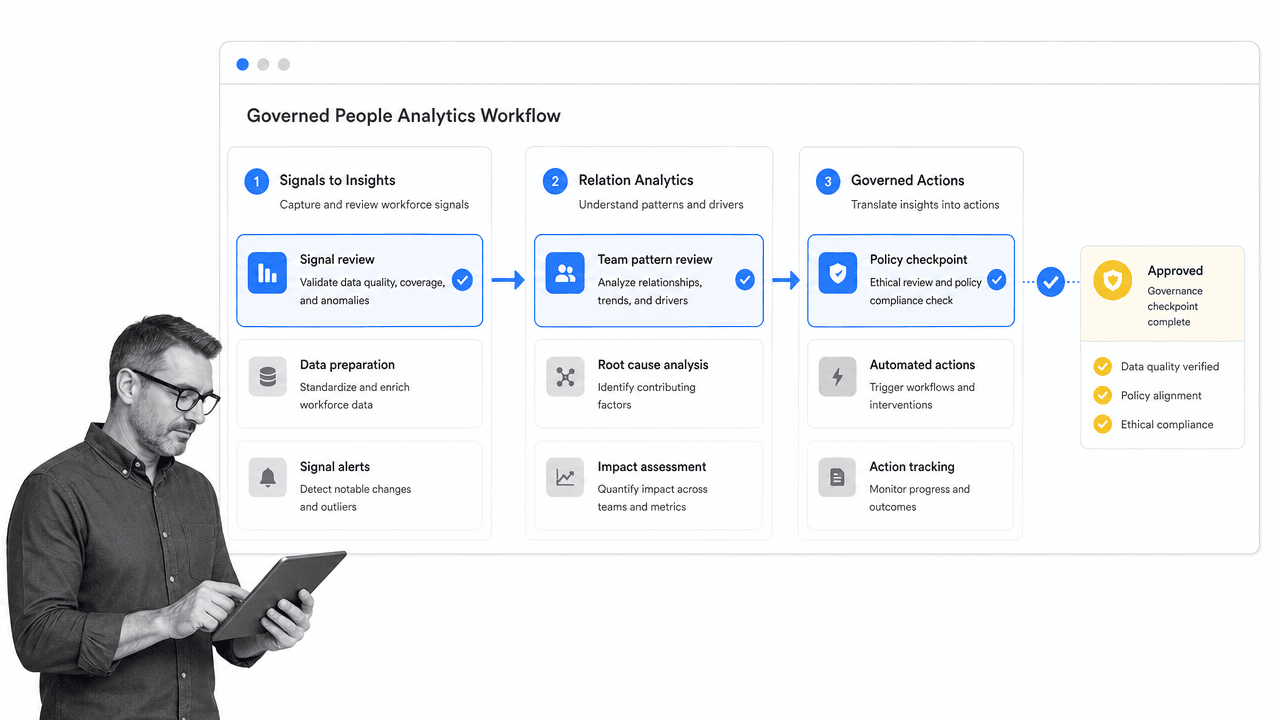
As people analytics becomes mainstream, employers want more quantities of data at higher qualities. The need for complex data requires better tools for collecting, processing, analyzing, and acting on it. That is where AI HR tools, workflow automation, and governed analytics systems come in. For a deeper look at that layer, see our guide to AI HR tools.
The durable shift is not that HR gets a robot brain. It is that HR decisions increasingly sit inside systems: an onboarding workflow, a review cycle, an access request, an engagement follow-up, a compliance task, or a manager action plan. Big Data becomes useful when it moves from dashboard observation to governed execution.
Relation analytics: Not your grandma’s data stream anymore
While we are talking about data volumes, I might as well mention relation analytics. It is like people analytics, but more. Kinda a theme here, huh?
The main difference is that people analytics often focuses on quantitative facts about an individual: work history, tenure, education, role, performance data. Relation analytics looks at how people interact with each other: influence, efficiency, motivation, trust, and informal networks. Basically, relation analytics does not just focus on data about an individual. It is that, sure, but it is also about how they interact with all the other individuals you are collecting data on.
TL;DR: Relation analytics is not just what people do, but who they do it with.
Just like the current realm of people analytics covers a ridiculous array of data, from the number of full-time employees in your organization to the number of times a single employee uses semicolons, relation analytics is a pretty ambiguous term for an as-yet-fully-defined category.
Say you have a team of 20 people: 11 women, 2 nonbinary people, and 6 men. A traditional people analytics report might show tenure, role, location, education, and performance distribution. Relation analytics asks what is happening between them.
Who does everyone go to when a decision has to be made? Who quietly keeps the project moving? Who has influence without a title? Who is always brought in after a problem begins? Who is being left out of the information stream? Basically, relation analytics is about the actual social system underneath the org chart.
That makes relation analytics powerful. It also makes it sensitive. Once you start mapping relationships, you are close to mapping trust, influence, and behavior. That requires transparency, consent, clear purpose, and human judgment.
Just because you can doesn’t mean you should
In a remote part of Siberia, Dr. Sergey Zimov and his son, Nikita, have been working on a multi-generational project to recreate a rare ecosystem to combat climate change. Science says that replacing forests with grassland can help slow thawing permafrost and reduce the sudden release of dangerous climate accelerants.
It is an ambitious project, but since 1996, they have had success seeding grassland and importing large grazing animals such as horses, musk ox, and bison to sustain the man-made biome now known as Pleistocene Park. The provocative part is the woolly mammoth. Revive & Restore and other researchers have continued exploring de-extinction work, while coverage from Smithsonian Magazine shows how complex the idea remains.
The crucial element to the success of Pleistocene Park, however, is the woolly mammoth.
No, this is not another Michael Crichton style Jurassic Park reboot. The point is simpler: a technical ability does not automatically settle the ethical question. Editing an Asian elephant’s DNA and getting a fetus to term in an artificial environment would be only the first of many challenges such a scheme would face.
Ross Anderson made that point in The Atlantic: species do not exist as isolated code. They exist in ecosystems. Change one part and the effects move outward. Even ecologists can only model so much before real-world consequences begin anew.
The same is true for people analytics. A company may be able to predict attrition, monitor sentiment, map relationships, infer engagement, or flag performance risk. That does not mean every prediction should be made, every signal should be collected, or every intervention should be automated.
That caution is not theoretical. At Pilanesberg National Park, young male elephants once became brutally aggressive after older bulls had been removed from the social system. BBC Earth and Living on Earth both covered how reintroducing mature males changed the behavior of the teenage elephants. The obvious lesson is that no animal, person, or employee exists alone. Systems have consequences.
The same caution applies to governments, industries, and companies building people analytics systems. Data collection, processing, and analysis can solve real problems, but it can also create discriminatory results, extreme stress, and exposure when it is handled without careful consideration.
Privacy law has moved quickly since early Big Data optimism. The EU’s GDPR Enforcement Tracker shows more than 3,000 tracked cases and over EUR 6.3 billion in fines. Brazil’s LGPD remains a major data protection regime. India replaced the old PDPB conversation with the Digital Personal Data Protection Act, 2023. California’s CCPA was amended by CPRA, and the California Privacy Protection Agency keeps current law and regulation materials. Australia passed the Privacy and Other Legislation Amendment Act 2024. Canada’s Bill C-27 did not become law in the 44th Parliament, but the debate around privacy and AI governance is not going away.
The lesson for HR is not to stop using data. The lesson is to design safeguards into the work: consent, data minimization, access controls, audit trails, bias review, human review, and a clear path from insight to action.
Process Street is built for that kind of governed execution. Teams document HR policies and procedures in Docs, run onboarding, performance review, engagement follow-up, access, and compliance workflows in Ops, and use Cora to monitor process risk, missed steps, and drift. People analytics creates insight. Governed workflows make sure the response is consistent, auditable, and humane.
Prediction is very difficult, especially if it’s about the future.

Tech and Big Data create an ever-changing landscape that, realistically, we can only guess at. That change will keep getting faster, and it will create obstacles, dilemmas, and complications we do not have easy answers for.
As we look at the future of Big Data and its uses, it is important to consider both the benefits and consequences. People analytics can improve employee experiences, address social inequities, and help organizations manage work more intelligently.
It can also violate trust, disenfranchise particular groups, or cause tangible harm to an individual. The possibilities for Big Data are no longer limited by imagination, so caution, consideration, and empathy cannot be left behind in the wake of ambition.
Sure, it is cool if you can reconstruct a woolly mammoth, but how will that mammoth affect the wider sphere?
As one Mr. Samuel L. Clemens is often credited with saying: Data is like garbage. You had better know what you are going to do with it before you collect it.
Use people analytics to make work better. Then build the policies, workflows, and review loops that prove it is being used that way.