

At 5 AM on August 29, 2005, the largest drainage canal in New Orleans, the 17th Street Canal, was breached by torrents of water an hour before Hurricane Katrina struck the city. Levees and floodwalls failed in 50 different locations, flooding 80% of New Orleans. No doubt the system failed. But which system?
Experts later pointed to budget cuts, outdated engineering, and weak process infrastructure. The same pattern showed up during the coronavirus pandemic: the most damaging failures were not single mistakes. They were overlapping breakdowns in governance, communication, data, tools, and accountability. This post looks at five COVID-19 system failures, why they happened, and how stronger processes can reduce the same risk in your own organization.
Why do systems fail?
System failures happen for a variety of reasons – some so improbable that we never consider preparing for them. When we say system failure, we generally mean some computer-related problem, and those are fairly easy to diagnose and solve: bad code, faulty hardware, or a missed update. A computerized system failure is specific, predictable, and, most importantly, fixable.
That doesn’t mean these failures are a pleasant experience; most often they’re associated with that stomach-dropping moment when the Blue Screen of Death (BSoD) appears and you can’t remember the last time you backed up your hard drive.
Or maybe that’s just me. (Note to self: back up hard drive.)
2020 has seen its share of system failures, much to the somewhat Schadenfreudian delight of meme creators everywhere. And, while many of these failures have involved technology – what aspect of our lives doesn’t these days? – I’m going to focus on the more human reasons these failures happened, and what can be done to prevent human error going forward.
Before we really get into the why of system failure, though, we need to understand what exactly a system is.
What makes a system?
For our purposes, a system is a set of processes or procedures designed to achieve a certain result. As long as these processes and procedures are up-to-date and working properly, the system runs smoothly and efficiently.
Systems are found in every part of the natural world from the way the universe works to subatomic activity. It’s no surprise then that we’ve adapted that structure to create our own system designs.
However, while natural systems – for the most part – run automatically with minimal errors, designed systems require much more precision in development and closer attention in maintenance.
What is system failure?
System failure, simply, happens when a process breaks. This break could happen for a number of reasons:
- The process is outdated;
- Design issues;
- Poor process adherence;
- Lack of understanding;
- Lack of ownership.
Any one of these issues – or all of them together – can create a system failure. It’s easy enough to combat most of them, however, and, generally, additional systems are put in place during development to make sure these things don’t happen. Designs are tested, adherence is monitored, updates are applied as needed.
No problem. So how do catastrophic failures like the levees in New Orleans, or any given Tuesday in 2020, happen when there are safeguards in place?
The only way a complex system can experience a true catastrophic failure is through multiple, simultaneous points of failure.
This means that, while it’s reassuring to find a single point of error or a scapegoat to blame, that is rarely going to provide a long-term solution.
What have been the biggest COVID-19 system failures so far?
To say that 2020 has been a year is an understatement.
Fires. Floods. Hurricanes. Earthquakes. Coronavirus. Volcanos. Locusts. Murder frickin hornets.
Seriously, have you seen those things?
And yes, it could be argued that we have very little control over when events like these happen, or how severe they might be. Some have even made the argument that no one could have predicted a year like this.
Human responsibility in unusually extreme and increasingly frequent natural events is the subject of several, several books – and will likely be the subject of many more.
1. WHO, IHR, and where it all went wrong
Update: The institutional lesson is still current. WHO says the International Health Regulations now include amendments adopted in 2024 and in force from September 19, 2025, and the World Health Assembly adopted the WHO Pandemic Agreement in May 2025. Those changes reinforce the same point: emergency systems need clear reporting triggers, authority, funding, and follow-through before the crisis starts.
The World Health Organization (WHO) is seen as the international expert on all things health. In response to the numerous epidemics that had plagued Europe (no pun intended), WHO introduced the International Health Regulations (IHR) in 2005.
Among the many things the IHR covers, it outlines criteria for determining whether an event is an international public health crisis, the rights and responsibilities of the member countries, and how public health events that have the potential to cross borders should be handled.
So, if there’s an infrastructure in place to handle events like COVID-19, why have so few countries been able to contain the outbreak, and what has the WHO been doing all this time?
As part of the United Nations (UN), WHO is supposed to be politically neutral, and, in theory at least, it is. However, WHO also relies heavily on funding from its member states. As a result, WHO officials must also practice careful diplomatic strategy, which sometimes means releasing information too soon without proper confirmation, or sitting on information so long it actually inhibits action.
Recent budget cuts over the past few years from some of WHO’s largest financial supporters have left the organization in a precarious position.
Systems require resources. Without those resources, the system fails.
Lack of funding created two bottlenecks:
- Without enough money to fund its programs, WHO essentially has its hands tied.
- With funding dependent on political agendas, WHO is indebted to its donors.
An offshoot of underfunding, it became apparent that the IHR was flawed. Without financial support, WHO lacked the authority to enforce the laws set out by the IHR. However, the IHR itself allowed member states to “opt out” of participating in the event of an emergency situation.
In other words, during an international emergency, such as a pandemic, member states could decide not to follow the criteria outlined in the document meant to handle international emergencies.
And many chose to do just that.
This leads us to another primary system failure of the pandemic:
2. It was totally under control

Update: The 2019 Global Health Security Index ranking remains a useful warning, not because the score was meaningless, but because preparedness scoring did not guarantee operational execution. Later pandemic reviews showed that capability on paper can collapse when leaders minimize risk, public health teams lack authority, and early warnings do not trigger action.
On October 24, 2019, the Global Health Security Index was released ranking which countries were best prepared to handle an outbreak.
The US ranked number one. The UK ranked number two.
How, then, did the two most prepared nations in the world become the two biggest failures in terms of COVID-19 response?
(In number of cases and deaths, the US also ranked first, with the UK again coming in second.)
There are various reasons (which I’ll go into), but they all fall under one umbrella: nationalist exceptionalism.
Both governments were guilty of believing that they could afford to ignore the advice of WHO, devalue public health systems, and refuse to acknowledge the seriousness of the outbreak.
While New Zealand, Singapore, and South Korea experienced great success through science-based strategies, and Italy – one of the initially hardest-hit nations – urging other world leaders to take immediate action, both Trump and Johnson stubbornly insisted on reinventing the wheel with a square cardboard box.
Separately.
The inconsistency of data, response, guidance, and policy led to mass confusion, conspiracy theories, and violent confrontations between “anti-maskers” and frontline workers. Videos popped up all over social media of nurses, store employees, and even other customers being physically and verbally assaulted by those asked to wear masks.
And those were the minor incidents.
Which brings us to the next domino in our little line…
3. How not to communicate during a pandemic
Update: The UK COVID-19 Inquiry’s first module, published in July 2024, made the communication lesson harder to ignore. Preparedness and response structures need defined ownership before public guidance changes, or each region, agency, and frontline team is forced to interpret the system for itself.
While actor Matt Lucas’ take on Prime Minister Boris Johnson’s press conference about lifting the three-week-turned-three-month lockdown in the UK was hyperbolic, it perfectly summed up the confusion many felt about the PM’s message.
The following months would see a split between the four nations of the UK, with Scotland, Wales, and Northern Ireland increasingly frustrated with Johnson’s measures, or lack thereof. By the end of summer, the easing and enforcement of restrictions from Downing Street applied only to England, with the rest of the UK forcefully requesting residents of England keep their distance.
Meanwhile, in the US, Trump passed the responsibility to state governors, which led to a complicated situation where states had different lockdown procedures and restrictions, and some weren’t under lockdown at all.
In the limbo of who could do what, when, and with whom, hostilities only intensified as small businesses, low-income families, high-risk individuals, minority communities, and those with non-COVID chronic conditions continued to be overlooked and disproportionately affected.
It wasn’t a lack of planning that left so many in uncertain and untenable situations; when it came to the various lockdowns that were implemented, the system failed through inaction, a lack of clear communication, and an unwillingness to collaborate with epidemiologists and other world leaders.
4. The app that launched 1,000 problems

Update: The first NHSX app failure was not the whole story. The later NHS COVID-19 app launched in September 2020, closed in April 2023, and government-cited research credited it with preventing cases. That makes the systems lesson sharper: the failed part was not the idea of contact tracing software, but the rollout, architecture, interoperability, and governance around it.
“We have growing confidence that we will have a test, track, and trace operation that will be world-beating.” – Boris Johnson, May 20, 2020
It seemed like a simple system:
- Someone who tests positive self-isolates for the quarantine period.
- The NHS identifies recent contacts and notifies them.
- These contacts self-isolate and get tested.
- If they test positive, their contacts are identified.
- Rinse and repeat, as needed.
NHS Track and Trace was intended to identify, contain, and reduce the spread of coronavirus throughout the UK. £10 billion was invested in the program under the promise that the virus would soon be controlled, and British life would return to normal.
A month later, after being trialed and downloaded by tens of thousands, the app was scrapped in favor of the system developed by Google/Apple.
By this time, however, lockdown regulations weren’t the only divisive factor among the four UK member nations. Dissatisfaction with Johnson’s proposed app led Scotland, Northern Ireland, and Wales to each develop their own test and trace systems.
By June, the United Kingdom had essentially become four autonomously operating governments with their own strategies for handling the outbreak. Not only was the UK isolated from the world; England became isolated from the rest of the country.
First Minister of Scotland, Nicola Sturgeon, frequently clashed with Johnson over what steps to take. As numbers in Scotland began to drop, support for Scottish independence increased, and some even wondered if the entire union should be dissolved as England continued to struggle with infection rates.
As the summer progressed, surveys indicated that only a quarter of cases in England were actually being identified, and senior civil servant Alex Cooper admitted only 37% of people were being identified.
By September, three to four more people requested testing than there were tests available, and Dido Harding, head of the system, admitted the increased demand in September was a surprise.
“As schools came back we saw demand significantly outstrip planned capacity delivery. … None of us were able to predict that in advance.” – Dido Harding
While poor planning and tech problems (more on that later) undoubtedly contributed to the ineffectiveness of the Test and Trace system, one factor caused the most damage: an excessively centralized structure.
Due to centralization within England, the specific needs of different localities weren’t taken into consideration – including barriers of language, access to technology, and working hours – which meant that people who needed information weren’t being communicated with effectively.
5. Devils, details, and data entry
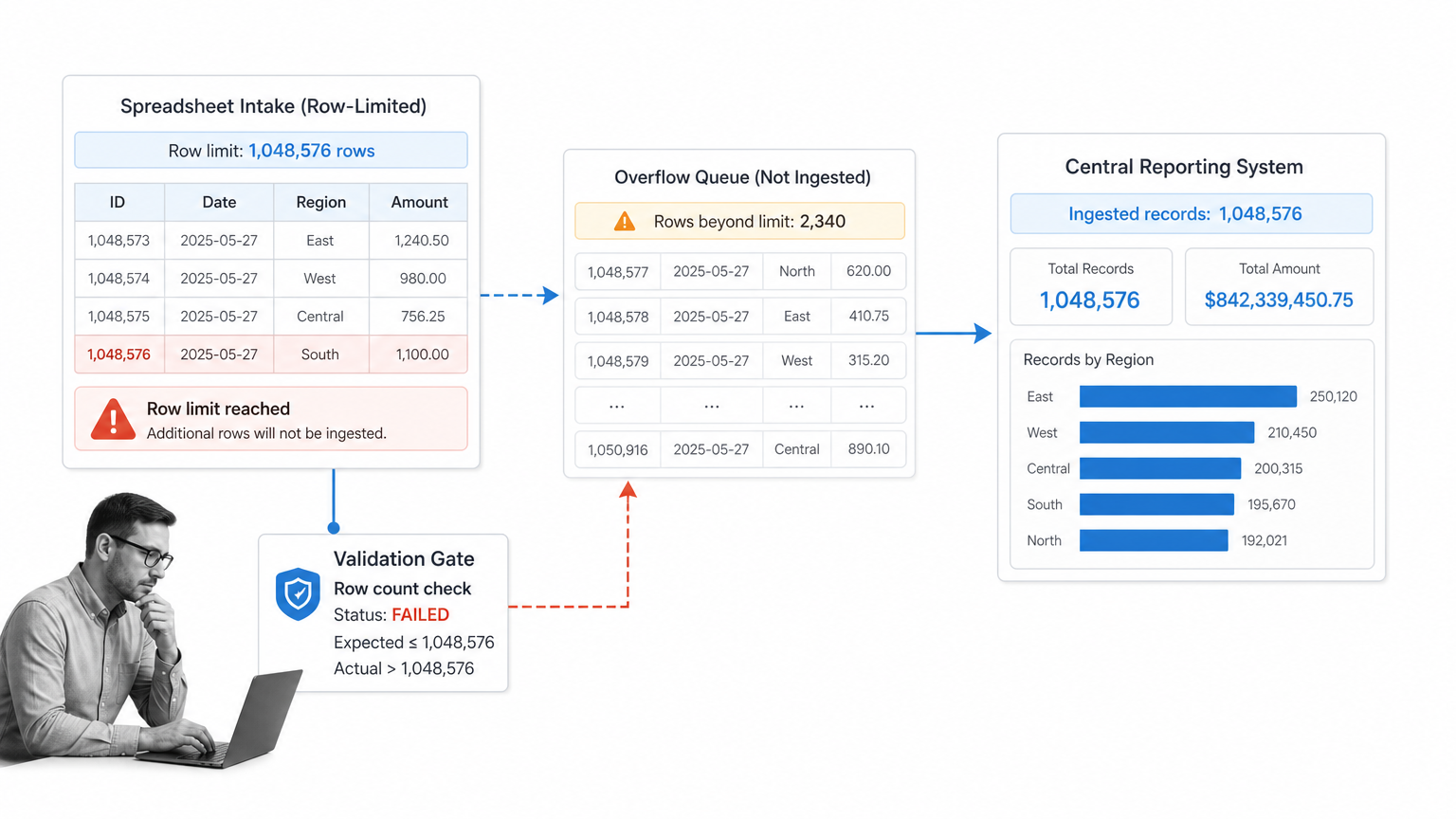
On October 4, the UK experienced its highest record of new cases with 22,961 daily cases. For perspective, October 2 had a little less than 7,000.
What happened on October 3 to cause that difference of roughly 16,000 cases?
An Excel spreadsheet, as it turns out.
Public Health England (PHE) chose an old file format (XLS) to automatically pull the test data into Excel sheets that could then be uploaded to the central system. As a result of using XLS, each template could only hold about 1400 cases.
Once the total number of rows were filled, any excess data was just… not included.
While the glitch only took place during the course of a single week, it does bring to light the importance of using the right tools for the job.
And, perhaps, if you need to collate and store the data of tens of thousands of people, something more sophisticated than a spreadsheet is what’s called for.
Hindsight 2020
In each of these instances, you can easily see how multiple failures contributed to the overall whole. In each case, if there had been a single problem, it could have been dealt with and resolved with little or no fallout.
However, because of the multiple broken processes in these examples, the systems remained ineffectual for far longer than they should have, and there were dire consequences for that. Many of these consequences will have long-lasting effects well after the initial failure.
In fact, only in the case of the spreadsheet glitch have processes been rebuilt and the system fixed.
How to (easily) build a fail-proof system
As a company, you likely won’t experience system failure on this scale, but these instances do highlight how serious system failures can be. A broken system can mean a loss of clients, time, resources, and, worst-case scenario: people’s lives.
Any system failure, however minor it seems initially, can have effects that your organization never fully recovers from. As such, making sure your systems keep running at their best, it’s vital to be prepared for possible failures – even the seemingly unpredictable.
Without a strong foundation…
To create strong systems, you need to have strong components – in other words, well-designed processes.
Sure, when you first started your organization, keeping all the procedures in your head, or even “winging it”, from time to time was no problem. But your organization’s grown and more people are involved in more tasks. If you don’t have those foundational systems laid down, sooner or later, something is going to break.
Building processes can seem daunting. Where do you start? Where do you find the time? How do you know what steps the process should have?
Fortunately, designing and implementing processes can be broken down into four key steps:
- Identify opportunities in the workflow.
- Plan how to improve the current process.
- Execute the changes.
- Review whether or not the new process is successful.
And then you go right back to Step 1: Identify, because process improvement should be a continuous action.
Start with your most necessary process and break it down into smaller tasks. It doesn’t have to be perfect the first time around, and it doesn’t even have to be pretty. The important thing, in the beginning, is to get a rough framework for the process.
Once you do that, share it with your team and get their feedback. The best way to optimize your processes is to get as much feedback as possible, particularly from those who’ll be using that process the most.
Those team members will know exactly what needs to be done, and exactly what can go wrong, and be able to provide you with the best insight into preparing for and avoiding those issues.
Once you start documenting your processes, you’ll want to build a knowledge management system to keep your systems organized and accessible. It doesn’t help anyone if employees have to ransack the office before they can use a particular process. A knowledge base allows you to store all of your processes, procedures, and systems in one, easy-to-find location.
Creating a digital knowledge base has the added advantage of simplifying the update process. Rather than print out new appendices, or even an entirely new manual, every time a process is changed or updated, digital knowledge bases can usually be updated instantaneously.
How Process Street can help
Process Street is a Compliance Operations Platform that helps teams turn critical procedures into governed, auditable workflows. Docs keeps policies versioned and approved. Ops turns those policies into assigned workflow runs. Cora monitors execution, flags risks, and helps teams improve the process before small misses become system failures.
The practical lesson is simple: document the process, assign ownership, run the work the same way every time, and review whether the process is actually working. If you want to catch weak points earlier, start with process monitoring, then connect the findings back into the workflows people use every day.
Becoming comfortable with imperfection
I admit: this has not been the most cheerful post I’ve ever written. So let’s end on a high, and look at what can happen when systems are built well, with strong processes and a good foundation.
“Our economy, our society, we’re losing out because we’re not raising our girls to be brave. The bravery deficit is the reason why women are underrepresented in STEM, in C-suites, in boardrooms, in Congress, and pretty much everywhere you look.” – Reshma Saujani, Founder/CEO Girls Who Code
Reshma Saujani is a CEO, lawyer, speaker, author, investor, podcaster, activist – the list goes on. In 2012, she noticed a flaw in the system: the number of women in computer science – which had never been huge – was decreasing, rapidly. The biggest drop off of girls in computer science happened between the ages of 13 and 17.
The problem, she realized, wasn’t a lack of interest or ability; it was a lack of support. Girls were not being encouraged to take risks and explore in the same way their male peers were, and it had long-lasting effects for the rest of their lives.
Saujani wanted to change that. She adopted the mission: teach girls to be brave, and to do that, she used computer science. Saujani founded the international nonprofit, Girls Who Code, and enrolled 20 girls in 2012. In that first year, she noticed that, not only were the students learning to code, but they were also learning to be brave. They were learning to take risks, and allow themselves to be less than perfect.
“Coding is an endless process of trial and error, trying to get the right command in the right place, with sometimes just a semicolon making the difference between success and failure. Code breaks and falls apart. … It requires perseverance. It requires imperfection.” – Reshma Saujani
Those 20 girls in 2012 grew into 300,000 girls in all 50 states in 2019. According to their annual report, the organization has shifted the gender gap in K-12 computer science classrooms to have closer parity and projects closing the gender gap in entry-level tech jobs within the next seven years. Their 80,000 college-aged alumni are declaring computer science majors 15 times the national average.
That is what a successful system can accomplish.
How do you protect your systems from failure? And if you’re really brave – what’s been your worst system failure? Let us know in the comments!