

Only 9% of information security professional believe their organization has effective incident response processes. The biggest issue? Well, you’re reading Process Street so you probably guessed it: the lack of standardization. Almost half of the respondents to the SANS Incident Response Survey said that their lack of a formal incident response procedure was holding them back and causing security issues.
It’s not even like preparing for serious security incidents is wasted time or that you’d be going overboard with precautions; 61% of companies have experienced critical incidents in the last two years — that includes data breaches, unauthorized access, and denial of service attacks.
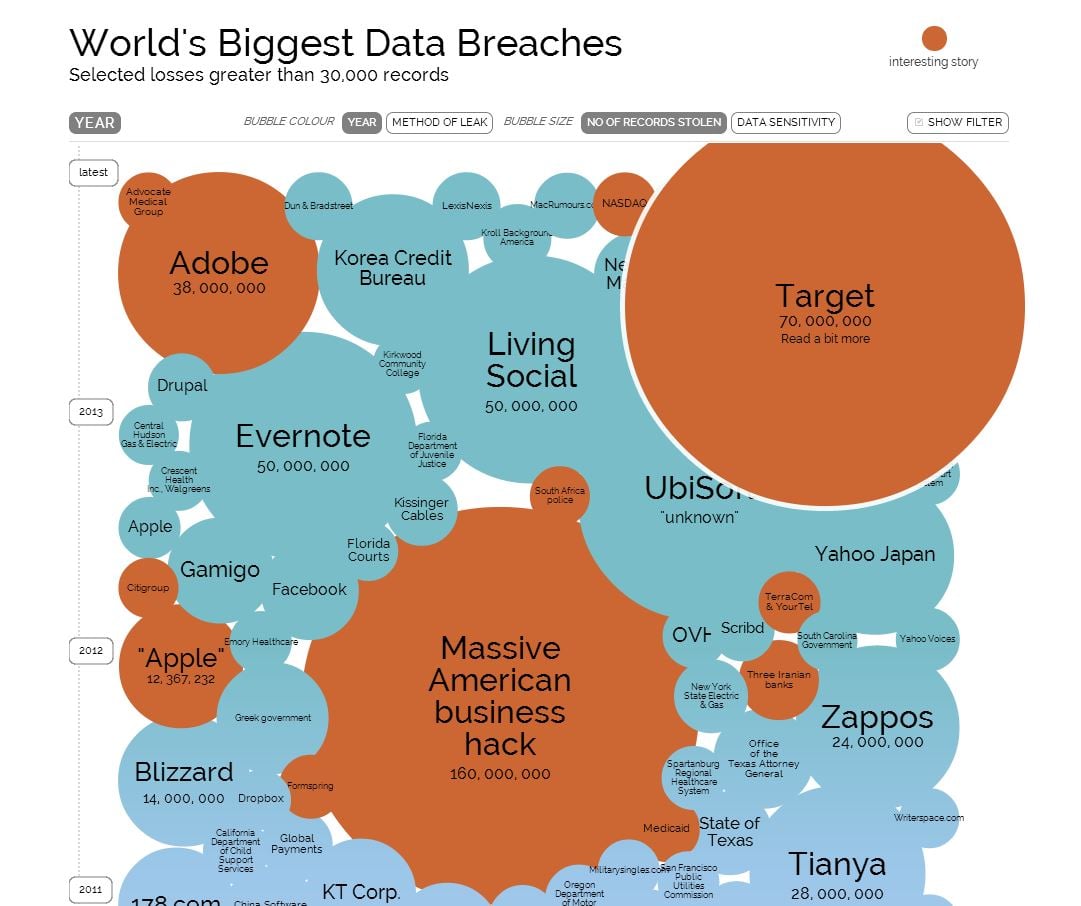
High profile companies like Evernote, Apple, Target and Equifax are always going to be under threat because of their size, but their infrastructure should match the threat level. If multi-billion dollar corporations are falling flat when it comes to information security, it goes to show that businesses of every size need to be extra careful.
Are you one of the 61% of companies that has suffered an attack? Or maybe you’re in the majority that could do with a real incident response standard operating procedure?
This article will go through each step of the incident response process. It also contains a checklist you can add to your Process Street account, customize, and run for each new incident.
Open the full checklist in a new tab
How to get the best results from this incident response checklist
This checklist is built with conditional logic so it dynamically updates to match the nature of the event.
For example, depending on the specified source of the breach, the checklist can show or hide system-specific tasks for Linux, Windows, etc.
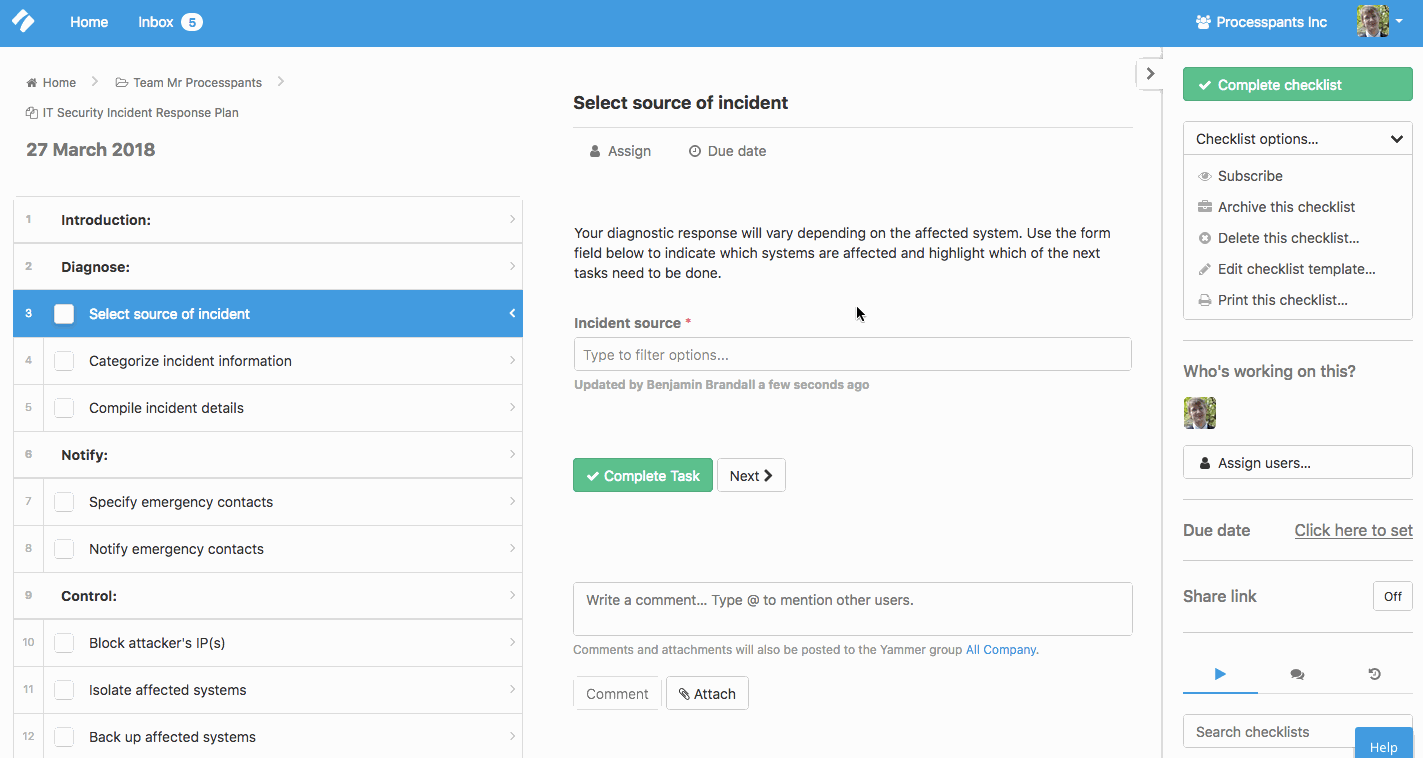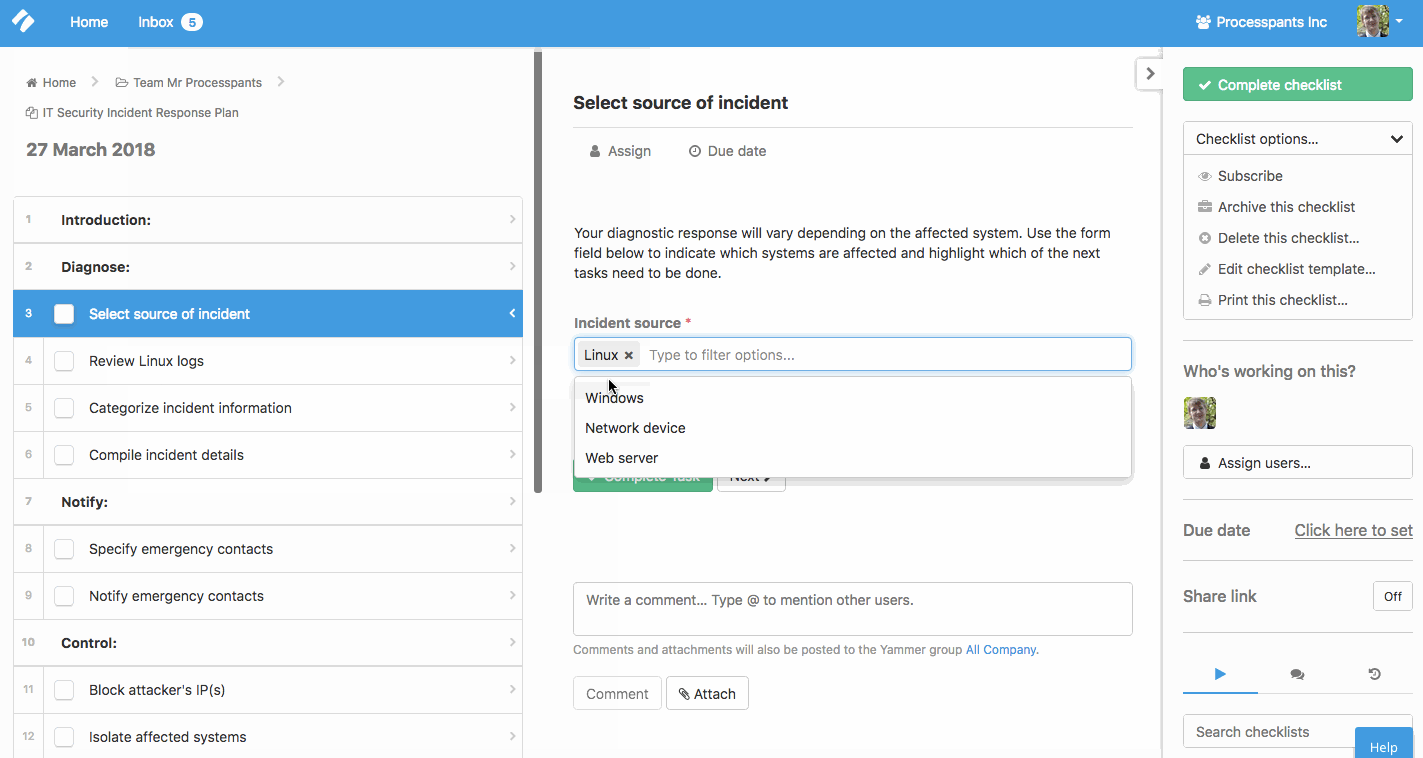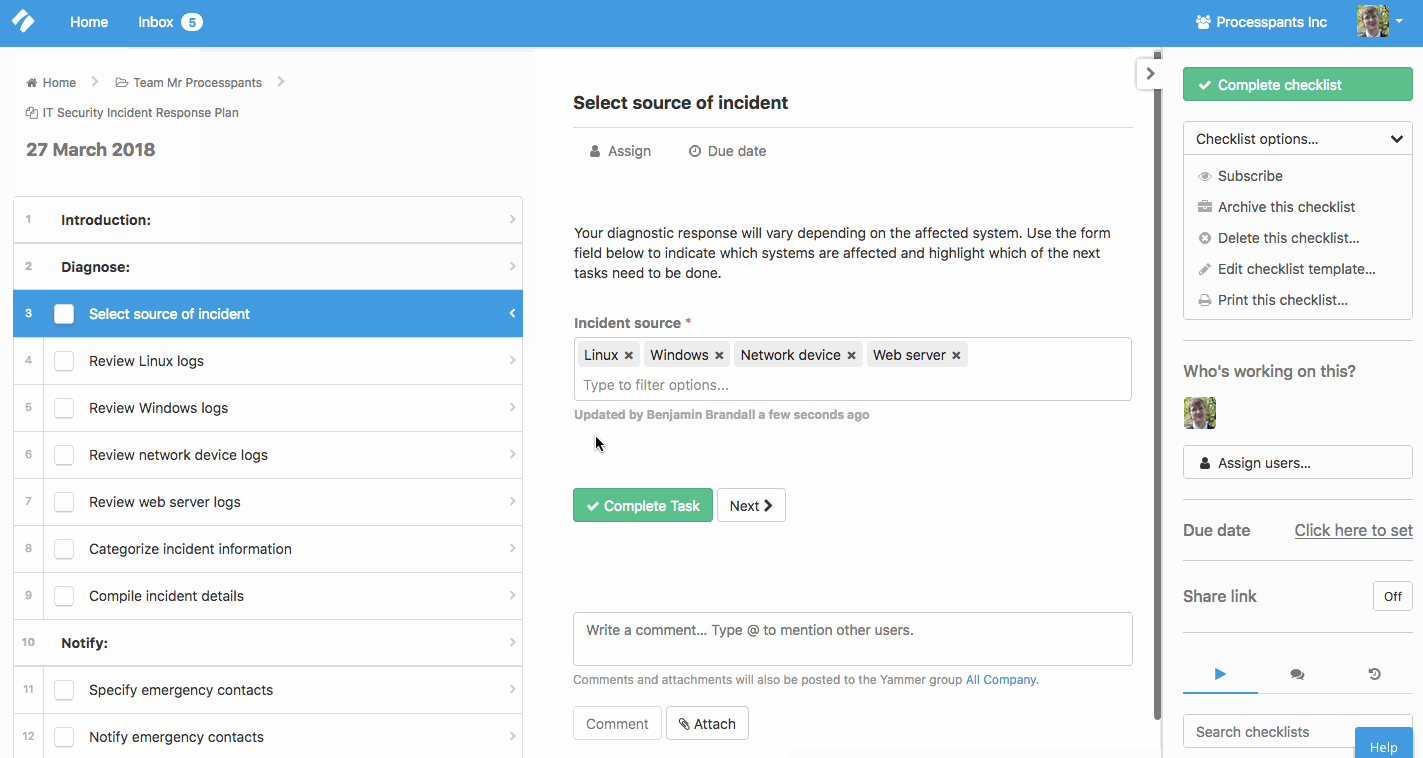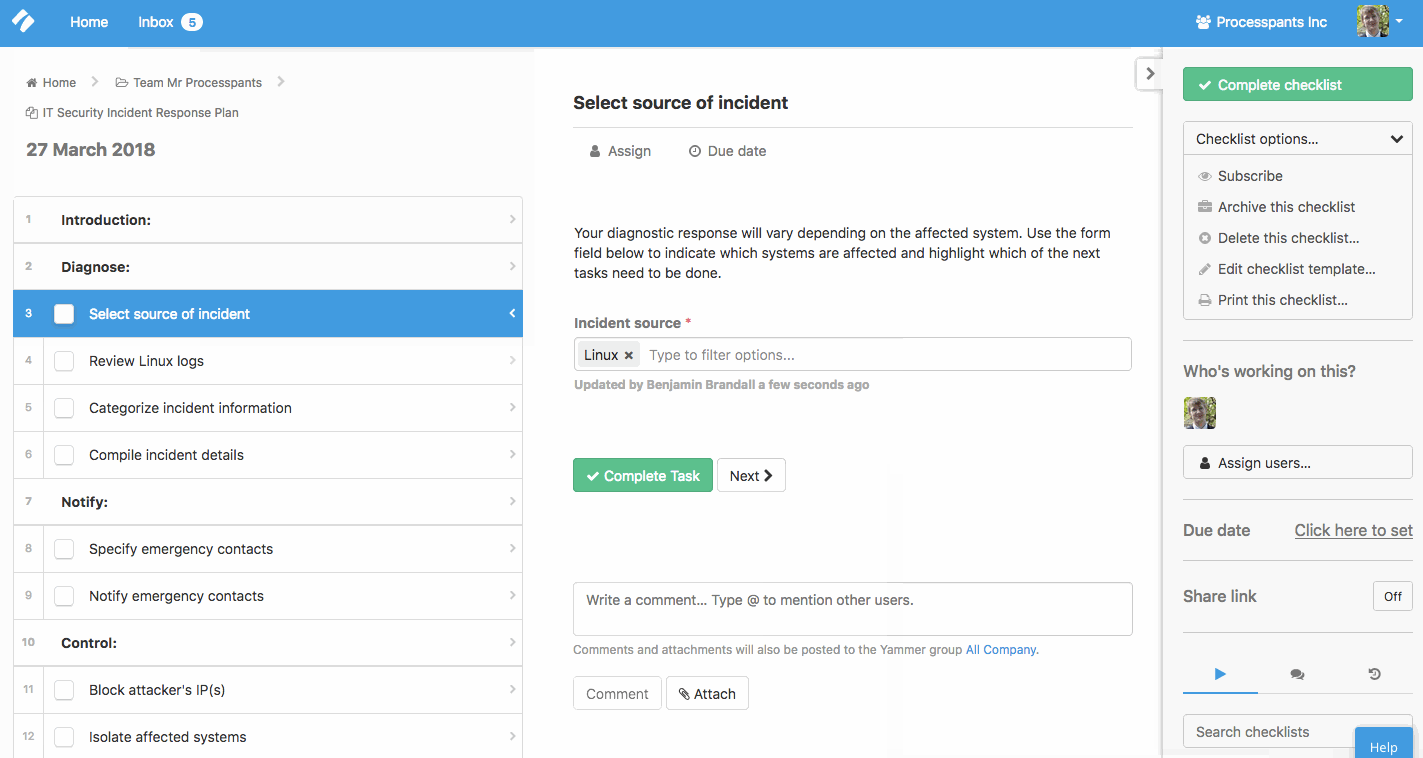
To set this up in your own account, get the checklist here and edit it. You’ll see a button for Conditional Logic at the top of the screen, which will allow you to set up rules.
Here are the exact rules I used in the gif above:
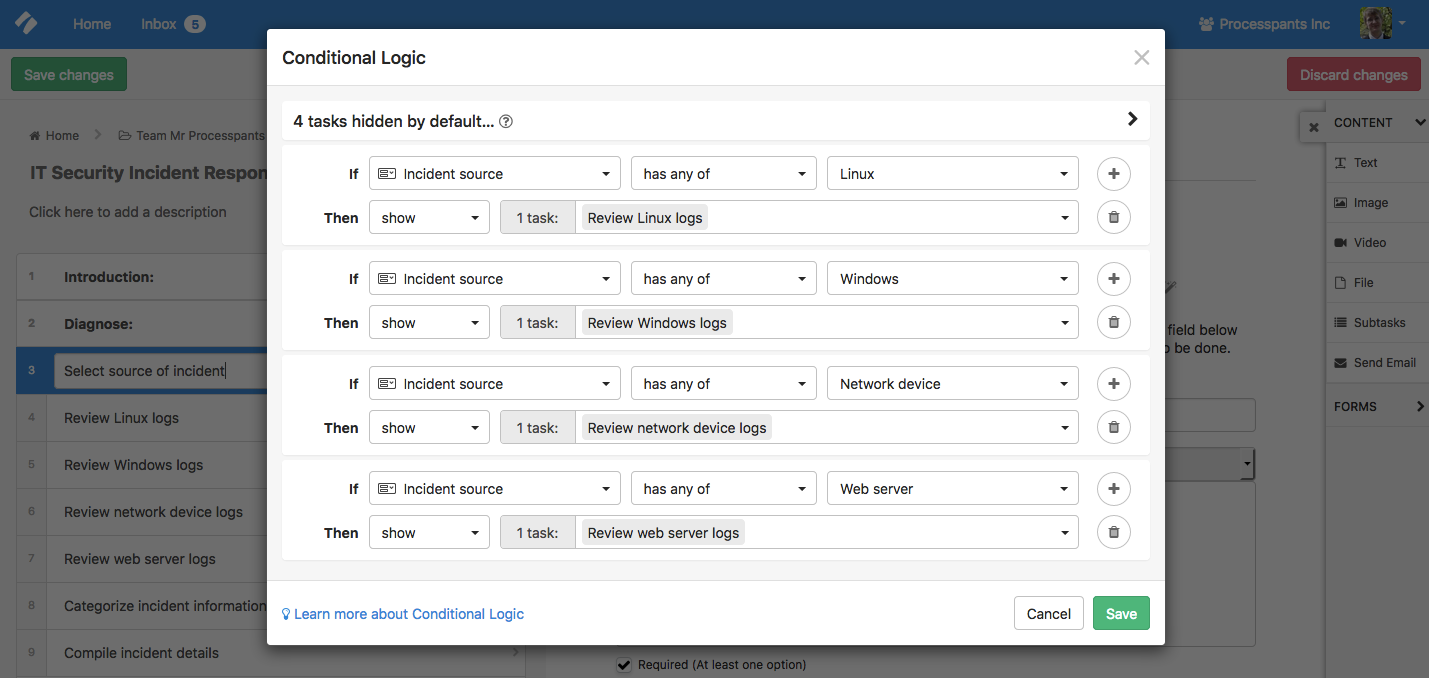
To summarize, tasks 4 through 7 are hidden by default. They appear when the incident source form field is filled with the name(s) of the affected systems. This helps you focus on only the tasks that are relevant.
Throughout the checklist, there are also form fields for recording information of the incident and the email addresses of your IT emergency contacts:
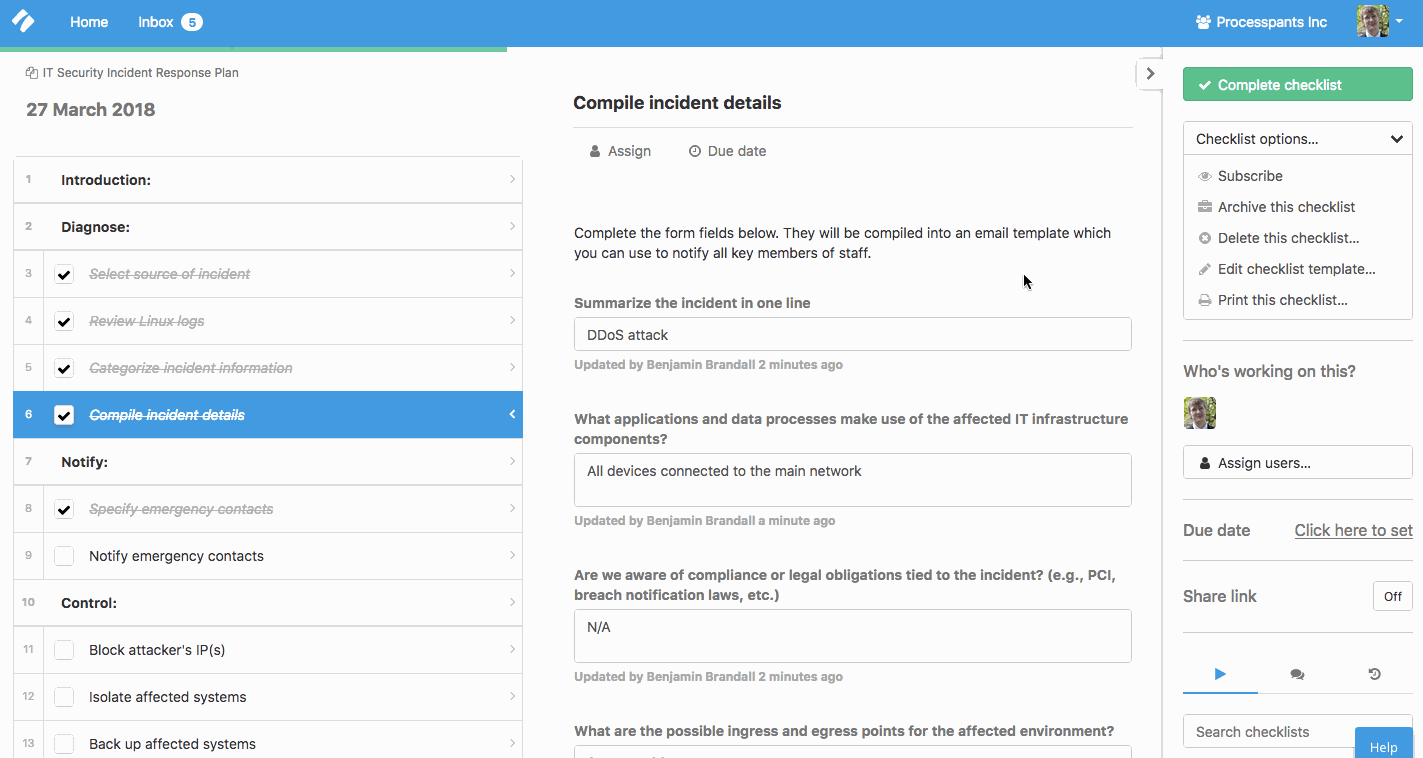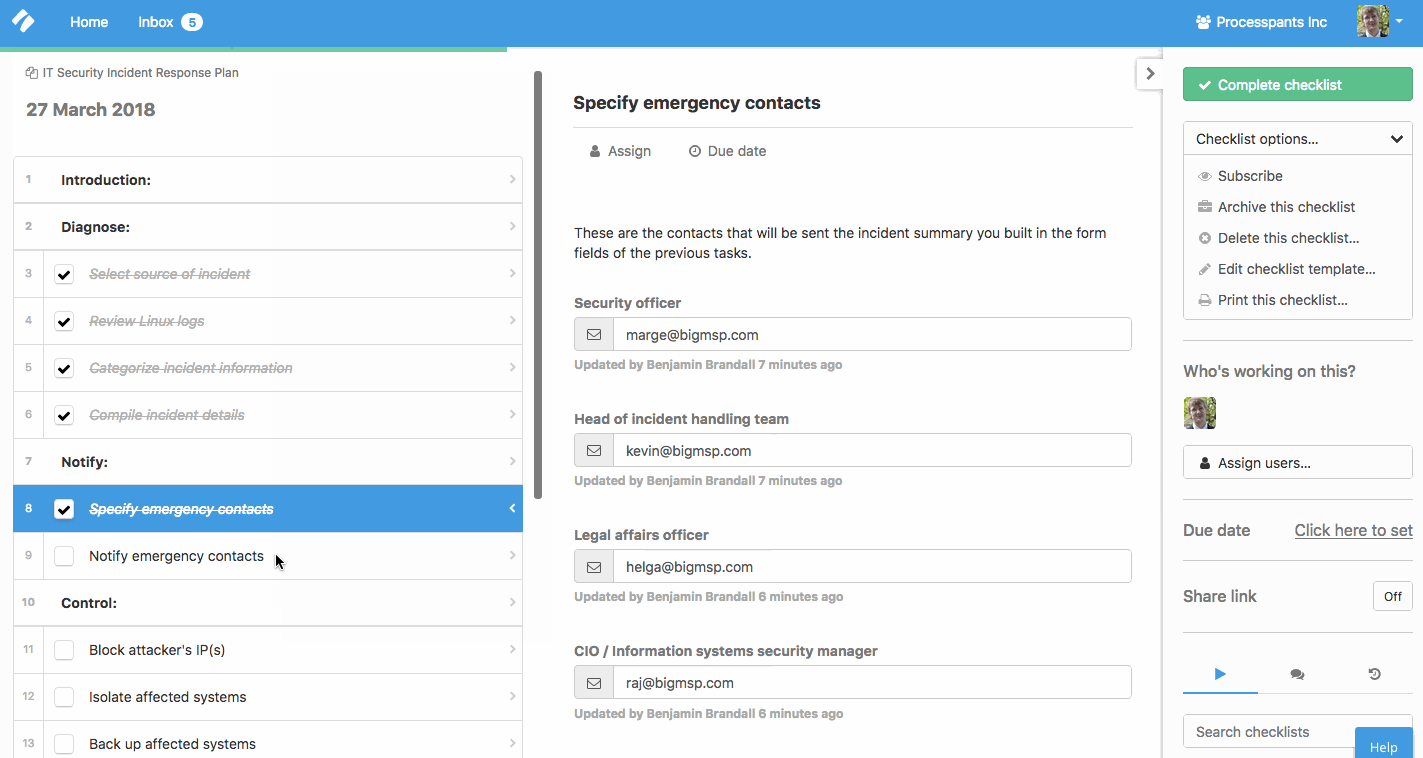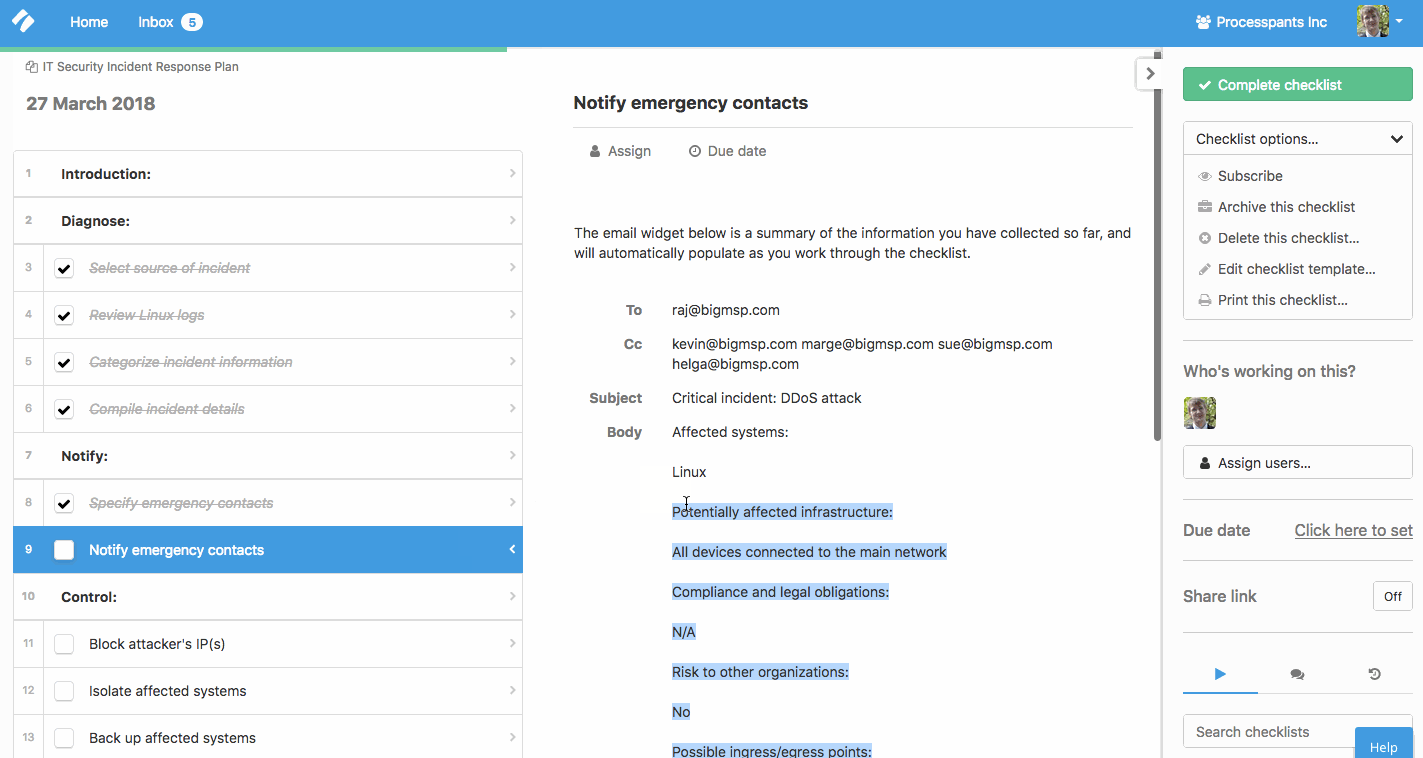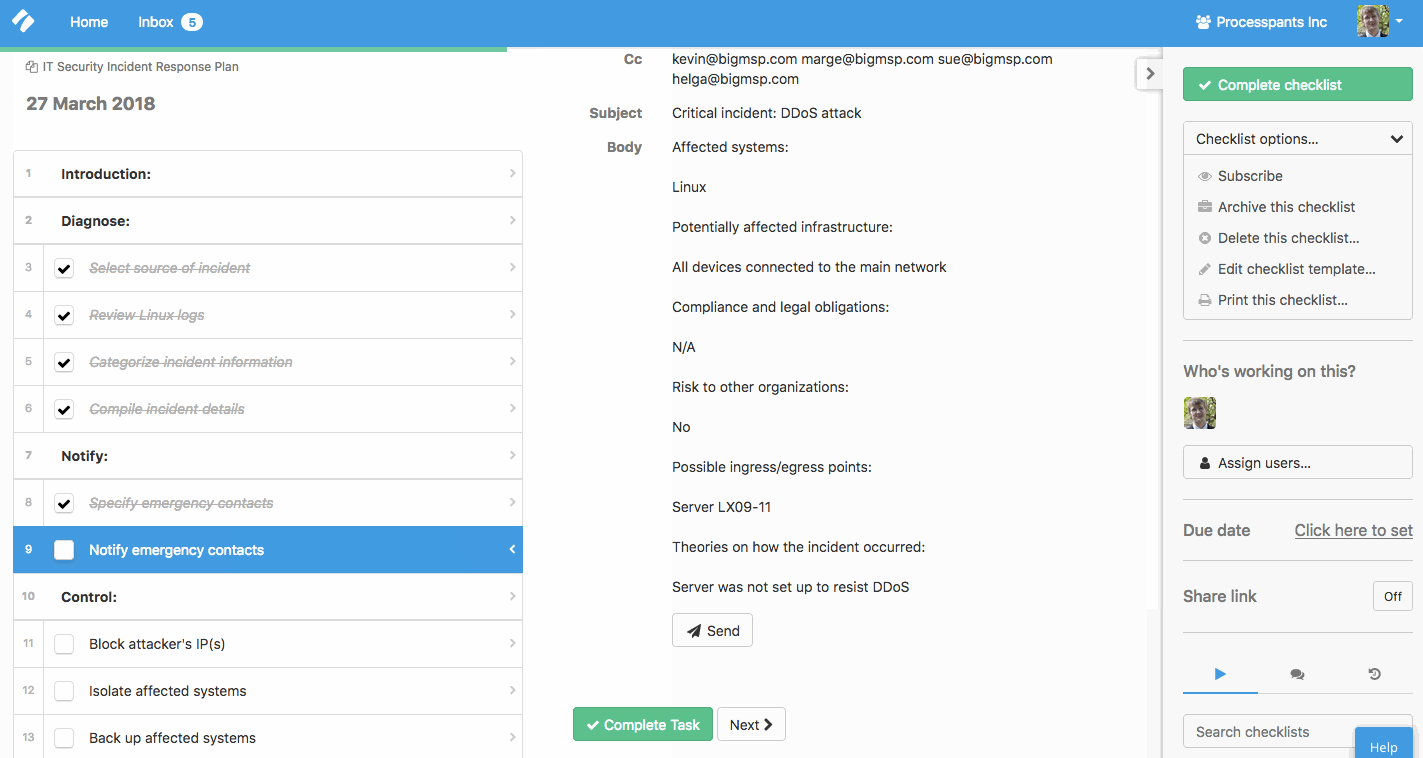
As you can see in the gif above, these emails — complete with the details of the incident — feed into a ready-made email you can use to notify the key staff members. This helps you save time in a critical situation and keep everyone in the loop.
The IT incident response plan, broken down
The actual steps taken in an emergency vary greatly depending on your company’s architecture and the nature of the attack. However, this post and checklist will give you a basis to work from that you can gradually build out and perfect over time.
The purpose isn’t to give you a ready-to-use checklist, but more to set you up with a repeatable, reliable and efficient system that will help you both in times of emergency and aftermath analysis. By recording your data in Process Street you can generate CSV exports, add other staff to the checklists, and get a quick overview on the status of multiple incident response efforts with Template Overview.
Broadly, your plan should cover:
Surface-level diagnostics
How do you surface an incident? Does it have to be flagged up once it’s already happened, do you notice it from suspicious logs, or do you catch it before it manages to create an impact? You should have a good process to monitor for potential or in-progress incidents, as well as good lines of communication between the IT department and those who need to use its helpdesk.
As well as proactive measures, you need systems for categorizing the issue once it’s caught and narrowing it down to the most crucial details:
- Summarize the incident briefly (scope, affected systems)
- What applications and data processes make use of the affected IT infrastructure components?
- Are we aware of compliance or legal obligations tied to the incident? (e.g., PCI, breach notification laws, etc.)
- What are the possible ingress and egress points for the affected environment?
- What theories exist for how the initial compromise occurred?
- Does the affected IT infrastructure pose any risk to other organizations?
This checklist includes form fields to help you document the initial incident details.
Communication with the triage team
Once the bare minimum amount of information that is required to investigate is gathered, the next system to get in place is efficient communication with the core security staff involved with incident handling. In a crisis situation, it’s important to get the key staff involved, either helping to settle the incident or managing those who are. This checklist collects staff email addresses and formulates the incident summary into a ready-t0-send email.
You can take it one step further by triggering the checklist from another application, and automatically filling in some form fields from the source application. For example, a new JIRA issue with a particular tag could trigger the incident response checklist to run and populate with the emails of the assigned members in JIRA. This kind of automation — and many more options — is available with our Zapier integration.
Damage control
The proper damage control procedure for every kind of incident should be easily available your runbook. Creating and maintaining a runbook means adding a little burst extra work the first time you do and document a task, but it does mean that you’ll be able to flawlessly remember the best way to resolve an issue:
“Will you remember how to do these things 6 months from now? I find myself having to re-invent a process from scratch if I haven’t done it in a few months (or sometimes just a few days!). Not only do I re-invent the process, I repeat all my old mistakes and learn from them again. What a waste of time.” — Tom Limoncelli, The Operations Report Card
In this incident response checklist, we have suggested some general damage control methods (isolating systems, capturing backups, removing malware), but the exact course of action will be highly variable because the concept of a technical incident is a very broad one. These steps are all processes in themselves which need documenting and optimizing over time.
Analysis and recovery
Analysis and recovery, which happens once the incident has been controlled, should be methodical and process-driven. In many cases, such as a case involving malicious software, it will even need special equipment. One precaution recommended by Lenny Zeltser is to use a disconnected laboratory laptop for analysis. Zeltser breaks the malware analysis process down to a few key areas:
- Examine static properties and meta-data
- Behavioral analysis: examine the specimen’s interactions with its environment.
- Static code analysis: understand the specimen’s inner-workings.
- Dynamic code analysis: understand difficult aspects of the code.
- Unpack the specimen on an isolated lab computer if necessary
- Perform memory forensics of the infected lab system
Again, these steps are all their own processes which need to be documented. If you’re just getting started with IT documentation, you might find a good starting point in large selection of pre-made processes:
- Weekly Website Maintenance Checklist
- Monthly Website Maintenance Checklist
- Quarterly Website Maintenance Checklist
- Yearly Website Maintenance Checklist
- Server Maintenance Checklist
- Server Security Checklist
- Information Security Incident Response
- SQL Server Audit Checklist
- Privileged Password Management
- Network Administrator Daily Tasks
- Network Security Audit Checklist
- Firewall Audit Checklist
- VPN Configuration
- Apache Server Setup
- Email Server Security
- Penetration Testing
- Cisco Router Setup
- IT Service Call Process
- Scheduled Maintenance Notification
- Patch Management
- Network Security Management
- Client Data Backup Best Practices
- Computer Maintenance Guide
- Inventory Management Process
- Server Setup Process
- Virtual Private Server Setup
- IT Support Process
- Helpdesk Management
- Vendor Management: Supplier Evaluation
- Vendor Management: Contract Negotiation
Credit for the incident response checklist’s guidance comes from several guides written by Lenny Zeltser, and I hope this post has provided you with a framework that combines Process Street’s facilitation of hand-offs and structured procedures with the general structure you need for an incident response plan.