

While it might seem new and intimidating, machine learning in business is already bringing massive benefits to companies and consumers alike.
From increasingly effective product suggestions to accurate journey time predictions and advanced customer analytics, machine learning is an incredibly powerful tool which lets you analyze every important aspect of your business without wasting human hours on the task.
But what exactly is machine learning, and how do you go from knowing that to actually using it?
“Instead of using labels to teach an AI what each object it’s looking at is, this DeepMind project teaches itself because it learns to recognise images and sounds by matching them up with what it can see and hear.
This method of learning is almost exactly like how humans think and learn to understand the world around them.” – Vaughn Highfield, How Google DeepMind is learning like a child: DeepMind uses videos to teach itself about the world
In this article we will cover:
- What is machine learning?
- Benefits of machine learning in business
- Applications of machine learning in business
- Different types of machine learning in business
- Real-world examples of machine learning in business
What is machine learning?
Although some use the terms interchangeably, “AI” and “machine learning” aren’t the same thing.
To prove it (and to explain what machine learning is), take a moment to think of an advanced machine from a book or movie, like The Terminator or Data from Star Trek.
These machines are examples of artificial intelligence (AI), seen in their ability to solve complex problems and act in a way that we would see as “smart”. For example, they could hold a conversation with a human rather than just saying “yes” or “no”.
Meanwhile, machine learning is an application of AI which lets machines analyze the data they’re given and learn from it without humans having to teach them. In this way the machine gets “smarter” by identifying patterns and the factors that cause them, which can be used to solve future problems more accurately.

{kind=link}
This learning model usually needs a human to start off the process with an initial thesis (“studying more gives better grades”) and the factors used to analyze it (“the amount of time studying vs the student’s final grade”), but that’s not always necessary.
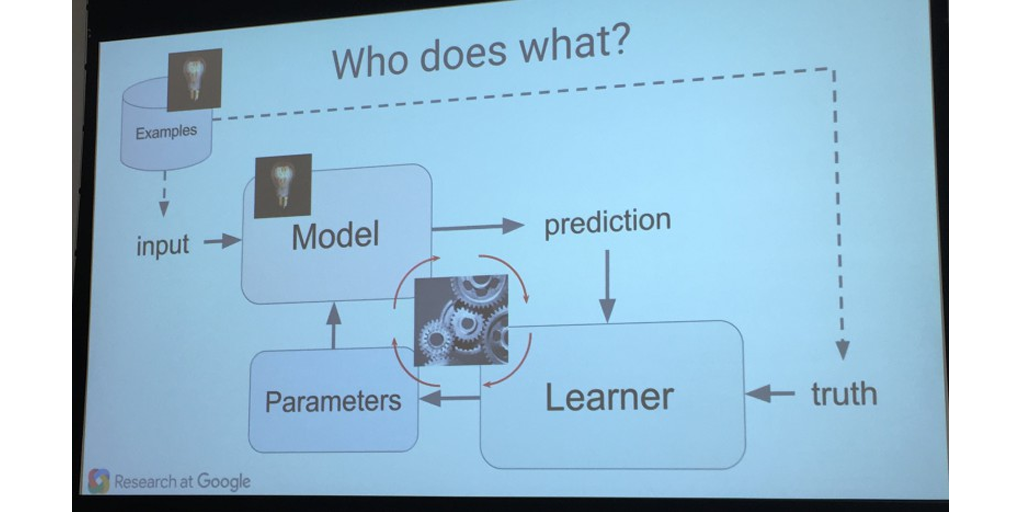
To take a bit of a deeper dive, a machine learning model is made up of three separate parts:
- Model
- Parameters
- Learner
Let’s take a quick dive into each.
Model
The “model” is your thesis statement. It tells the machine what it needs to be analyzing and iterating on as it learns more from the data it’s presented with.
Let’s say that you wanted to find out when you should take a break. Your model might start off as “the longer you work without taking a break, the less productive you become”.
This would give you a summary statement to make sense of the vast data sets machine learning requires to progress and a core principle that that data can be related back to.
The model doesn’t have to be a statement backed in any facts as long as it gives a frame of reference for the relationship you’re looking to analyze, such as the amount of time worked without taking a break vs how productive you are. The model will also be changed to fit the results of whatever data you give your machine to process.
{kind=link}
For example, as a machine analyzes data showing how productive you are against how long you’ve been working without a break, the model might change from “the longer you work, the less productive you become” to “working more than 2 hours without a break makes you less productive”.
Parameters
The parameters of machine learning are the things being assessed; they’re the data and factors which are analyzed to make iterations of the model. In our case, these would be “the amount of time worked without taking a break” and “how productive you are”.
Parameters will never change, and so are the constant guidelines which tell the machine what information it should pay attention to. If the model is a relationship statement, then the parameters are the items whose relationship is being assessed.
Learner
The “learner” is exactly what it sounds like – it’s the system by which the machine takes its findings, makes sense of them in relation to the model, and then alters the model to match that information. It uses your model, parameters, and a relevant data set to review the model and adjust it to match the relationship shown by the data.
For example, let’s say that your first data set showed that productivity increased as you worked but then dropped off after two hours if you didn’t take a break. The learner would then adjust the model to read “working for longer than two hours without a break reduces your productivity”.

{kind=link}
This is an area where machines have a huge advantage over humans, as they are able to process huge amounts of data and perform the complex equations required to learn from them much faster than the average human.
That’s why machine learning in business is so powerful. If you can get a machine to do all of your data analysis and number crunching for you, that frees up time for you to work on more pleasant (or creative) tasks. Not to mention that humans only have a limited capacity to crunch data before suffering burnout, whereas machines can just keep going.
Once the data you’ve given the machine has been assessed and the model updated, the entire cycle repeats with the next set of data. This continues either until the system is stopped or it runs out of data.
Benefits of machine learning in business
Machine learning offers numerous benefits for businesses, revolutionizing the way they operate and compete in a fast-evolving marketplace. Here are some of the key advantages:
Cost savings
By automating repetitive tasks and optimizing processes, machine learning reduces manual effort and enhances operational efficiency, resulting in significant cost savings for organizations.
Accurate predictions
Machine learning algorithms analyze vast quantities of data to generate prediction models, enabling businesses to make accurate forecasts about market conditions, customer behavior, and other crucial factors.
Competitive edge
With its ability to extract actionable insights from real-time data, machine learning empowers businesses to stay ahead of the competition and adapt quickly to changing market trends and customer demands.
Enhanced customer experience
By analyzing customer behavior and preferences, machine learning enables businesses to personalize their offerings, leading to improved customer satisfaction, loyalty, and retention.
Fraud detection
Machine learning algorithms can efficiently detect patterns of fraudulent activities, protecting businesses from financial losses and ensuring secure transactions.
Better decision-making
Machine learning provides business leaders with data-driven insights, enabling them to make informed decisions and allocate resources more effectively.
Deeper insights
Machine learning allows businesses to delve deeper into data, uncover hidden trends and correlations, and gain a more comprehensive understanding of their operations and market dynamics.
Applications of machine learning
Machine learning is not just a buzzword in the tech industry; it has become a powerful tool that has revolutionized various business sectors.
Its applications are vast and diverse, offering numerous benefits to organizations of all sizes. Let’s explore some of the key applications of machine learning in business.
Fraud detection
Financial institutions, e-commerce platforms, and even healthcare organizations benefit from machine learning algorithms that can efficiently detect patterns of fraudulent activities.
These algorithms analyze vast amounts of data, identifying anomalies and suspicious behaviors, ultimately safeguarding businesses from financial losses and ensuring secure transactions.
Customer segmentation
By analyzing customer behavior, preferences, and demographics, machine learning algorithms enable businesses to categorize their customer base into distinct segments.
This segmentation helps organizations understand their customers better, tailor their marketing strategies, and provide personalized experiences, ultimately improving customer satisfaction and loyalty.
Accurate predictions
By analyzing historical data and market conditions, machine learning algorithms can generate prediction models that forecast customer behavior, market trends, and even demand for specific products or services.
These accurate predictions enable organizations to make informed decisions, optimize their supply chain, and allocate resources effectively.
Recommendation systems
By analyzing customer preferences and past behaviors, these systems can suggest relevant products or services to individual customers, further enhancing the customer experience.
Optimizing business processes
By automating repetitive tasks and handling complex tasks more efficiently, machine learning reduces manual effort and enhances operational efficiency.
The streamlining of processes results in significant cost savings for organizations, allowing them to allocate resources to more critical areas.
Healthcare analytics
Machine learning algorithms can identify patterns and predict ailments, leading to early detection and timely intervention through analyzing vast amounts of patient data.
It not only improves patient care but also reduces healthcare costs significantly.
Sentiment analysis
By analyzing customer sentiment from social media platforms, reviews, and feedback, machine learning algorithms extract valuable insights about customer preferences, opinions, and sentiments.
This information helps businesses make data-driven decisions, improve their products or services, and deliver a more personalized customer experience.
Different types of machine learning algorithms
There are several types of machine learning algorithms that can be applied in business settings to extract insights and drive informed decision-making. Some of the most commonly used algorithms include:
Supervised learning
This algorithm involves the use of labeled data to train models and make predictions or classifications. It is used for tasks such as customer sentiment analysis, fraud detection, and predictive analytics.
Unsupervised learning
In this algorithm, the data is unlabeled, and the models are designed to find patterns or groupings in the data. This is useful for tasks like customer segmentation, market basket analysis, and anomaly detection.
Reinforcement learning
This algorithm involves an agent interacting with an environment and learning from rewards or penalties to optimize its decision-making. It is often used in optimization problems, recommendation systems, and game-playing.
Deep learning
This type of algorithm simulates the neural networks in the human brain, with multiple layers of interconnected nodes. It is widely used in tasks like image recognition, natural language processing, and voice recognition.
Ensemble learning
This algorithm combines multiple models to improve prediction accuracy. It includes techniques like random forests, gradient boosting, and stacking.
Clustering algorithms
These algorithms group similar data points together based on their inherent characteristics. They are useful for tasks like customer segmentation, anomaly detection, and data exploration.
Real-world examples of machine learning in business
Alright, let’s take a moment and dive into real-world applications of machine learning to give you a better sense of how it’s being used in our every day.
Process Street’s Process AI
Process Street is a process management solution that helps businesses automate workflows and streamline business operations.
In 2023 they released Process AI, a feature that harnesses the machine learning and natural language processing abilities of chatGPT to allow users to create ready-to-go, automated workflows by simply inputting a few prompts.
This feature saves businesses the time and headache of creating their own personalized processes from scratch and really changes the game in the field of AI-powered process management.
YouTube recommendations
YouTube is not new to the machine learning game. With 1 billion hours of content watched each day, YouTube has relied heavily on machine learning algorithms since 2008.
The main thing they provide is curated recommendations for all 122 million active daily users. Before the algorithm, recommendations were based on whatever had the most views.
Now, its system operates on over 80 billion pieces of information to recommend specific content for every user.
Other companies like Netflix now use similar algorithms for their own recommendations.
PayPal fraud detection
PayPal leverages machine learning to help identify and prevent fraudulent events from occurring.
To do this, PayPal uses certain data from its customers, like:
- Purchaser location
- IP addresses
- Spending habits
- Email addresses
- Types of products purchased
By using this data, its algorithm can detect unusual behavior and put a stop to fraudulent transactions before they occur.
Using machine learning algorithms has been a game-changer for PayPal’s overall cybersecurity efforts. Businesses and individuals alike are protected by the same measures.
MIT’s ICU Intervene
The Massachusetts Institute of Technology (MIT) Computer Science and Artificial Intelligence Laboratory created a program back in 2017 called ICU Intervene.
This machine learning algorithm gathers data from intensive care units (ICUs) and uses it to come up with treatments for patients along with explanations as for why.
While this has yet to be adopted by many hospitals, it has the potential to revolutionize patient care, especially when time is of the essence, like in an ICU.
The possibilities of machine learning in business are endless
We are still just scratching the surface of what machine learning will be able to do for business as we look to the future.
Even though it isn’t really new, we are still in the experimental stage. We are still learning about all the different ways it can be applied in order to make our lives easier.
But if you want to get a first-hand look at how to leverage this technology for your business today, then check out Process AI. You can either sign up for a free trial or book a demo to see its limitless potential.