
 Here at Process Street, we’re always advocating for companies to use data to help in making important decisions.
Here at Process Street, we’re always advocating for companies to use data to help in making important decisions.
But data on its own is not massively useful.
I could run an experiment right now and gather loads of data. But if that experiment was run poorly then my data will be poor. Which means any readings of that data will be poor too, leading to poor decisions.
Alternatively, I could run a really well structured piece of research and gather some great data, but if I don’t know how to properly analyze that data then my conclusions won’t be very good.
Simply having large data sets is not enough.
We need to structure our research well and then be able to interpret the results with a degree of rigour. Fortunately, having a good working knowledge of P-Values can help us iron out some alarmingly common mistakes. It can teach us:
- How to set up an experiment for meaningful data
- The importance of measuring your existing hypothesis against an alternative
- When results really are statistically significant, instead of just looking good
This knowledge will help us make better decisions and lead to greater success.
In this Process Street article, we’ll look at 4 key areas:
- What are P-Values?
- How do you calculate P-Values?
- Examples of P-Values in practice – A/B testing
- Why you need to set up a research process
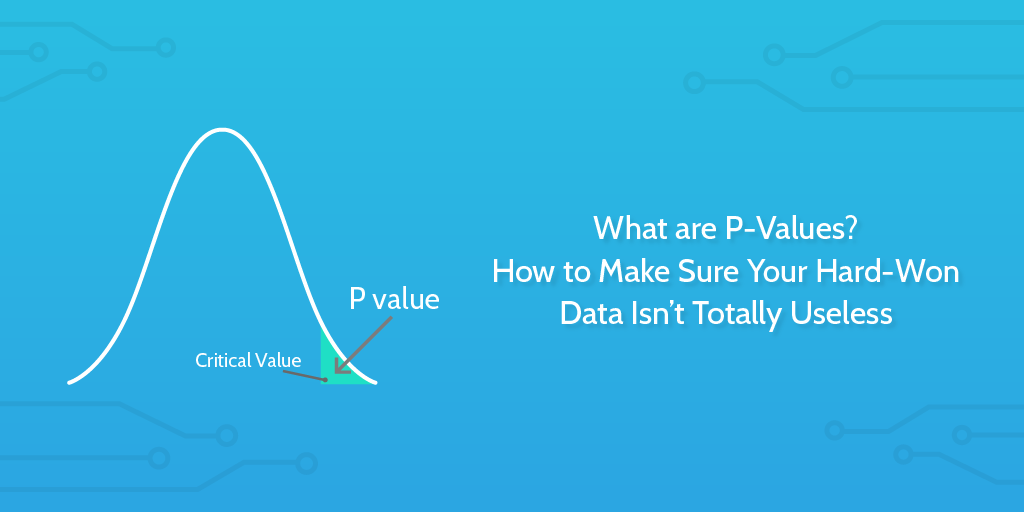
What are P-Values?
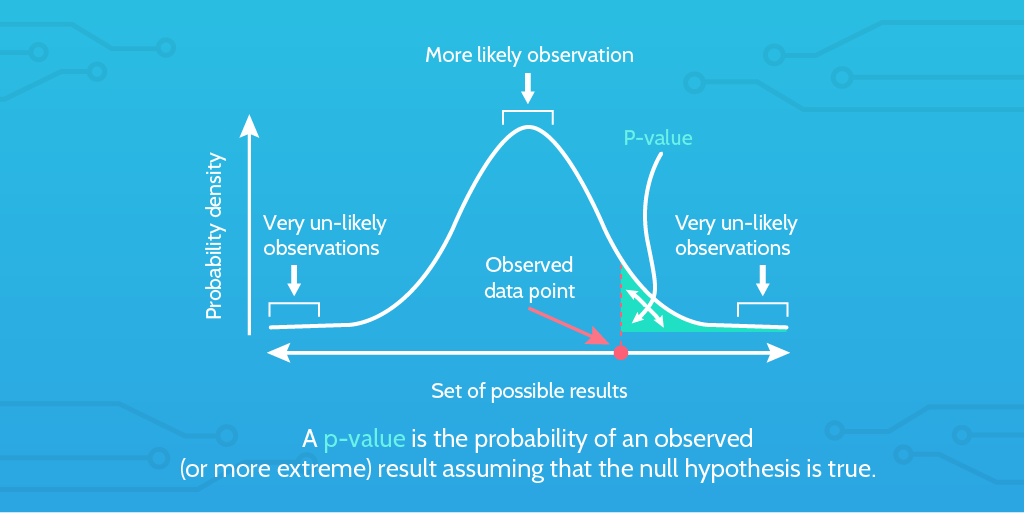
P-Values, or probability values, help us understand the statistical significance of a finding. The P-Value is used to test the likely validity of the null hypothesis. If the null hypothesis is considered improbable according to the P-Value, then that leads us to believe that the alternative hypothesis might be true.
Basically, they allow us to test whether the results of our experiments could have been caused simply by chance. Or, they demonstrate to us that we’re testing two unrelated things.
The P-Value is an investigative aid which can flag up things that need to be researched further.
It can validate some gut feelings, or it can serve to demonstrate that there does not appear to be a relationship between two factors; saving you time, energy, or wasted resources pursuing a fruitless goal.
Check out this short video below for a bitesize intro to how the P-Value came to be developed. The video also briefly highlights the misuse of P-Values in certain spheres.
If you’re not particularly statsy then you may have already lost interest.
But don’t worry!
Let’s pick apart some little concepts to understand them better.
What is a null hypothesis?
If you’re measuring the relationship between two things, then the null hypothesis is the assumption that there is no relationship between the two things.
Pretty simple actually.
In order to test the relationship between two things, you must first provide evidence that a relationship exists.
So, for any result to be statistically significant it must have a high probability of rejecting the null hypothesis.
Rejecting a null hypothesis assumes that an alternative hypothesis is true. It just doesn’t tell us specifically which alternative hypothesis is true.
Which means that a rejected null hypothesis tells us there is a good chance that the two things we’re testing have a relationship relevant to the testing parameters. It just can’t tell us any details about that relationship.
What is an alternative hypothesis?
Think of the alternative hypothesis as an active hypothesis.
If the null hypothesis assumes nothing happened, or there is no relationship between two things, then the alternative hypothesis suggests something did happen or there is a relationship between two things.
This alternative hypothesis is likely to be your current best working theory, which you now want to pit against a null hypothesis to see whether there’s clear statistical evidence for your working theory.
Not all forms of statistical hypothesis testing employ an alternative hypothesis, famously Ronald Fisher’s model.
How do you calculate P-Values?
 First off, you don’t necessarily need to know how to calculate P-Values off the top of your head. There are plenty of handy calculators which can do the job for you:
First off, you don’t necessarily need to know how to calculate P-Values off the top of your head. There are plenty of handy calculators which can do the job for you:
- GraphPad lets you calculate P-Values from Z, t, F, r, or chi-square.
- EMathHelp has a calculator which lays out instructions to explain what’s happening.
- GoodCalculators provides a nice graph along with your results to help you visualize the output.
You might think that using a calculator is a bit of a shortcut.
You would be wrong.
Working out P-Values manually can be tough and not a very efficient use of your time.
Nonetheless, we can lay out a quick example 7 step process to follow that will help you calculate your P-Value in certain conditions:
- Determine the expected results of the experiment. This could be based on a national average or previous data you have collected from similar experiments.
- Find out what your experiment’s observed results are. This will be your actual data which we’re going to compare against the expected results.
- Work out your experiment’s Degrees of Freedom. Basically, how many variables you have in your experiment minus 1.
- Use Chi-Square to compare the observed results with the expected results.
- Choose a significance level. The standard approach here would be to choose 0.05, or 5%.
- Check your scores against a Chi Square distribution table to approximate your P-Value. Or use one of the calculators above for a more specific answer.
If you want to learn how to do P-Values manually then you should take a look at some of the following resources:
- Penn State – Hypothesis Testing
- StatisticsHowTo – Calculate P Values With Excel
- WikiHow – Calculate P Values With Pictures
- MiniLab – Manually Calculate P-Values
Or watch this video from MathTutorDVD to get a really good in-depth breakdown with a great explanation of Left Tail, Right Tail, and Two Tail tests:
Examples of P-Values in practice: A/B Testing
What we’re going to do now is just show you a quick example of calculating P-Values in practice. It’s super simple but will hopefully take some of the intimidation away from P-Values so you can be confident to go deeper.
Now, I’m not going to show the real data – sorry – but I’ll run through a real life use case with some sample data which is a reflection of how the experiment was conducted.
We used Optimizely to run A/B testing on our website, trying to see the relationship between different messaging employed in promotional articles. Visitors to these articles would be interested in the product, and how they engage with the website after clicking should tell us about their intentions and wants.
The experiment was to A/B test two different promotional articles
We wanted to see if there was any difference in the engagement rates between the two articles, looking specifically at the titles. A conversion, for the purposes of this experiment, was simply whether the visitor clicked to see another page on the website – any page.
Attracting a visitor through clicking and then piquing their interest in the product is the purpose of the title and the following content, so that’s what we’re testing.
Let’s take two example titles (not the real ones used):
- Process Street is Home to Your Standard Operating Procedures
- Process Street Helps you Automate Tasks Within Workflows
These are both different statements of value for the Process Street product, and they appear to be different enough to maybe engage some visitors more than others.
What we want to test is whether or not changing the wording of that title – and the following messaging as a result – actually has any impact on visitor engagement rates. That is our null hypothesis: there is no relationship between the wording of the title and visitor engagement on the site as a whole.
We’re going to assume that title number 1 is the normal title for which we have historical data. So the engagement rates for that will be assumed to be the expected results.
Will the observed results – from changing the title to number 2 – have enough variance from the expected results for us to assume a relationship between title (messaging) and engagement?
Let’s look at our data:
Title 1 – expected results
- 10,000 visitors
- 8,000 engaged
- 2,000 left
Title 2 – observed results
- 11,000 visitors
- 9,500 engaged
- 1,500 left
Breaking this down with some math
Okay, as we’re only testing 1 variation against our expected results then our Degree of Freedom is 1. The DoF is n-1 where n is the number of variables. We have 2 variables. 2 – 1 = 1. Easy.
Here’s our chi-squared formula in the image below:
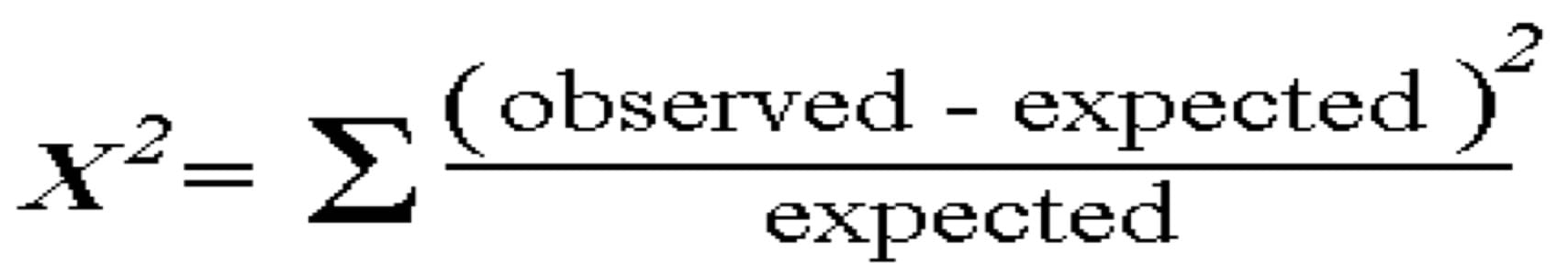
Because that badboy sigma sign is in front of part of the calculation, that means we need to run that part on each variable. So, our calculation will look like this:
x2 = ((9500-8000)2 / 8000) + (1500-2000)2 / 2000)
x2 = ((1500)2 / 8000) + (-500)2 / 2000)
x2 = (2,250,000 / 8000) + (250,000 / 2000)
x2 = 281.25 + 125
x2 = 406.25
Then we can check our final score against the chi-squared chart or just run it through the GraphPad calculator linked above. Chi-square score of 406.25 with a Degree of Freedom of 1.
You can see the chi-square table below:
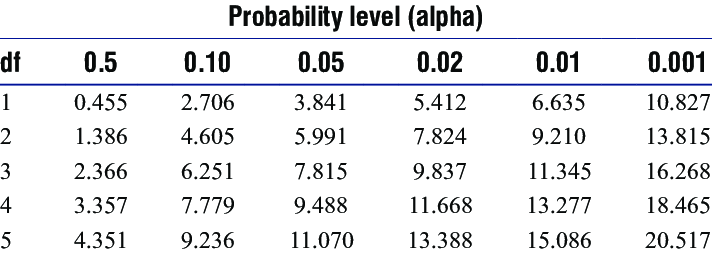
Because we only have a Degree of Freedom of 1, we use the top row of the table. The idea is that you go along the columns from left to right until you find a score which corresponds to yours. Your approximate P-Value is then the P-Value at the top of the table aligned with your column.
For our fun test, the score was way higher than the highest given figure of 10.827, so we can assume a P-Value of less than 0.001.
If we run our score through the GraphPad calculator, we’ll see it has a P-Value less than 0.0001.
This means the result is very statistically significant, and given the P-Value is so significantly below 0.05 we can can conclude the null hypothesis was false.
We have now essentially proven (in layman’s terms) that the messaging via the title impacts heavily on visitor engagement rates.
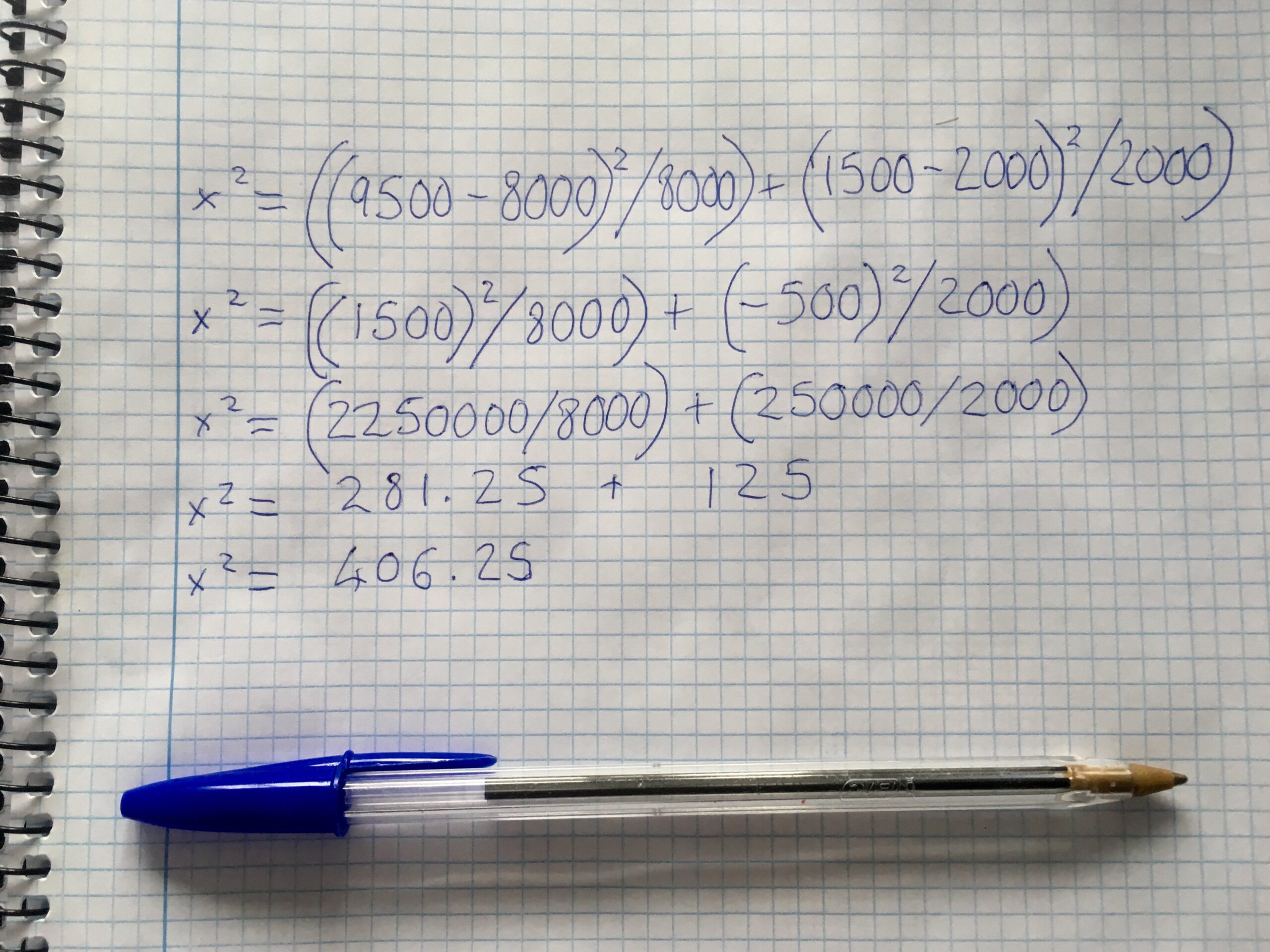
Now, I know what you’re thinking – with this data it was obvious. True. But most data will not look like this.
Hopefully, this little run through has helped you see how easy it can be to calculate P-Values in simple scenarios. Though, I recommend reading through the above resources if you want to construct even more complex comparisons and use cases!
Why you need to push a process on your research
When you’re conducting experiments like these in your business, you want to make sure the standard of investigation is as high as possible.
Bad analysis leads to bad decisions.
Wrongly interpreting data can lead to wasted time, energy, and resources across your team, and can damage your business in the long term.
Plus, it’s not only you who might be misinterpreting data. As Jerry Bowyer reports for Forbes:
Stephen Ziliak of Roosevelt University and Deirdre McCloskey of University of Illinois at Chicago have done the world of academic research the greatest, but least welcome, of favors. In their book, The Cult of Statistical Significance, in their own journal articles, and in the forthcoming Oxford Handbook of Professional Economic Ethics, they’ve meticulously gone through many thousands of journal articles and subjected them to scrutiny as to the soundness of statistical methods.
Against a variety of metrics, between 8 or 9 out of every 10 pieces of academic research contained some statistical issues.
That’s a lot.
In this FiveThirtyEight article, there is a video of researchers at a conference being asked on camera to explain P-Values. Most of them can come up with a definition but they struggle when asked to explain what that really means.
The point is, that if you want to do good research in your business you need to create a series of processes you can use to investigate things properly. A process makes best practice repeatable – which even professional researchers clearly need. Once you’ve written the process you can then follow it every time you do a similar piece of research.
- Gather sample data
- Assess for unaccounted variables
- Make sure data is consistent
- Run hypothesis testing
All simple things to do to make sure research is conducted wisely and from strong foundations. You can add to that list of considerations, put it in a coherent order, and BOOM you have a process.
Here at Process Street we’re always advocating for people to use processes to guide their work and the work of their teams; to build templates, run checklists, analyze template overviews. But we also encourage people to iterate, automate, and optimize these processes across their team.
This involves measuring, testing, comparing. All things that constitute research.
P-Values are not the be all and end all of research. They only help you understand the probability of your results existing through chance vs through changed conditions. They don’t really tell you about causes or magnitude or help you identify other variables.
But they do form one part of a larger set of research best practices which you should be able to employ.
What experience do you have with P-Values? When have they helped and when have they felt pointless? Let me know in the comments below!