

British Airways chief executive described the incident as “catastrophic” as 800 flights were canceled and 75,000 travelers were affected.
Flight compensation website flightright.com estimated that British Airways would have to pay around €61m to passengers for refunds alone under EU legislation. Add to this the cost of reimbursing angry passengers for unexpected hotel stays and other inconveniences, and the total financial damage to British Airways has been estimated at £100m.
Why? Someone turned their data center off and on again.
The entire airline was down for almost 2 days. This wasn’t a natural disaster, it was a process failure.
In this article, we’ll explore how to spot process failures before they occur using a system called Failure Mode and Effects Analysis (FMEA). We’ll assess an overview and then delve in deeper to ground our understanding and include a premade Process Street FMEA template to help you run your own assessments in future.
In this article we’ll cover:
- Your free FMEA (Failure Modes and Effects Analysis) template
- FMEA? What is Failure Mode and Effects Analysis?
- When do we use FMEA?
- Conducting and documenting Failure Mode and Effect Analysis: A user’s guide
- What happened to British Airways?
- Why did it happen?
- How can FMEA help us prevent this happening again?
Your free FMEA: Failure Modes and Effects Analysis template
If you already know what FMEA is and how it works, then you don’t need to read the rest of this article.
You only need to take this Failure Modes and Effects Analysis checklist. It’s free and comprehensive. Start using it in your business today!
Simply add the checklist to your Process Street account and you’ll have standard operating procedures in place to prevent disasters. Use it as a standalone template, or integrate it into your quality management system or your efforts to achieve agile ISO.
FMEA? Or, what is Failure Mode and Effects Analysis?

In it’s most simple form, FMEA is a method for identifying potential problems and prioritizing them so that you can begin to tackle or mitigate them.
It is how you approach your process management from a worst-case-scenario mindset. The perfect job for a pessimist.
Failure Mode and Effects Analysis can also be seen referred to as:
- Potential Failure Modes and Effects Analysis
- Failure Modes
- Effects and Criticality Analysis (FMECA)
Let’s start with some basic terminology to put things into context.
Failure modes – In any process, there are multiple ways that things can go wrong. Each of these ways you can think of are known as modes in the context of FMEA. It could be as simple as Jenny from accounting is off ill and this creates a problem for the accounts receivable department. Or it could be some hugely complicated problem in a massive manufacturing plant operating with automated technology. The core concept is still the same – the way something can go wrong in the process is seen as a mode of failure; a Failure Mode.
Effects analysis – This one is even simpler. What are the effects of an element of the process failing? Is it that Jenny’s work gets delayed a day? Or does Darren have twice the workload that day to keep things on track? But what is the effect of either of those outcomes on the broader company performance? What if the extra workload on Darren causes him to make some errors in the rush? Darren’s a nice guy, but he’s only human. Analyzing the effects of the initial problem means following the path of causality and investigating each potential problem from there.
If you want to know more about criticality analysis specifically, check out this article: Criticality analysis: What is it and how is it done?
So, within the framework of FMEA, the point of the exercise is to be able to identify all the different failure modes and then evaluate the potential damaging effects of each. It is vital to assess a number of different ways the effects can be damaging.
It could be how severe the consequences are, like with the British Airways error. It could be how frequently they occur; how many defects are present in every manufacturing batch, for instance. Or, it could be how elusive the failure is – difficult to stop, to see, or even to identify at the very beginning.
These potential effects need to be prioritized in order for us to tackle them systematically. Within the FMEA framework, we prioritize them in the order mentioned above: severity, frequency, ease of detection.
With priority defined, a company can begin to work through their long list of potential process failures either one-by-one or in related groups. By tackling the most dangerous problems first and the smaller harder ones last, a company is minimizing its exposure to risk as effectively as possible.
When do we use FMEA?
Short answer: all the time.
Maybe I’m being a bit hyperbolic. You don’t actually have to use FMEA all of the time, but at Process Street we operate with a strong focus on continuous iteration, improvement, and process optimization. Our guiding principles of business process management leave us with the intention of forever assessing and reviewing our internal processes, and FMEA is one method of process improvement; albeit, a highly risk-focused one.
The key use cases are really at moments of change. Continual iteration and assessment is encouraged, but not all businesses have the resources to have a dedicated process team and the time amongst their other workers to contribute to the investigation. Continually performing FMEA could result in greater inefficiencies than benefits for a company not equipped to do so.
The primary use case would be when you’re designing a new process. A process could take the form of a new way for a team to operate: new policies and procedures. Or, a new process could apply to providing a whole new service, where you’re entering into uncharted territory without previous similar processes to build from. It could even apply to a new product, in the manufacturing, distribution, or even customer use of that product as part of a wider risk assessment.
The framework is broad and general so that it can apply to a multitude of different scenarios.
When building a new process of any form, the process should be well documented and mapped. Once this design has been done, you can see the FMEA as a risk assessment of your concept. This technique should allow you to live out the process and explore what it will be like in action. As you discover the different failure modes, you will be able to adapt and improve the process before deployment.
FMEA is also used often in process reapplication or redesign. Perhaps you’re taking an existing process and looking to improve it, or to use it again in an adapted way on a slightly different use case. Whenever a process is to undergo significant change, FMEA is used to detect those potential new problems which could have arisen from the changes.
The real moment where you have to use FMEA is when you’ve failed to use it effectively in the past: when disaster strikes. This is the position British Airways is in now. After the problem has occurred, you need to launch a full investigation into what happened, why it happened, and how it could be stopped from happening again in future – don’t let the normalization of deviance set in!
Of course, you can’t stop every problem ever from happening. We’ve all seen Minority Report. But with effective use of FMEA, you can re-evaluate your processes to hopefully minimize the damage of these errors or incidents.

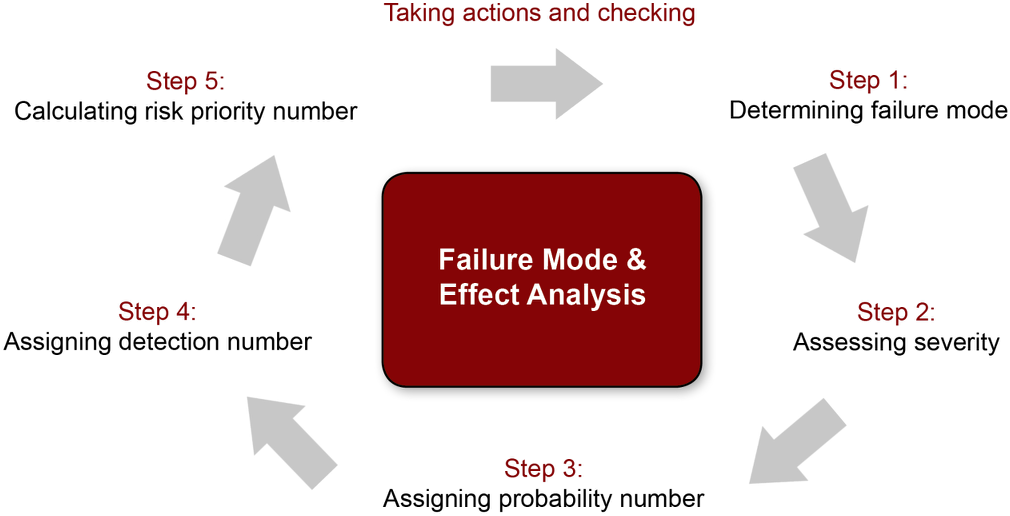
Conducting and documenting Failure Mode and Effect Analysis: A user’s guide
The first rule of Process Club: You always document Process Club.
Okay, that didn’t really work. Sorry.
Point is, you always need to document your processes. If you don’t have them documented, you’re going to struggle to understand and improve them in any meaningful way.
More than that, with FMEA you’re measuring risk – people’s lives might be at stake – so you need to show you’ve taken all the necessary measures to prioritize safety, at the very least. Documenting your processes is vitally important. You know this.
With FMEA, the recommended approach according to Nany R. Tague’s The Quality Toolbox is to utilize a grid system to categorize your analysis and then perfom calculations to determine priority. You can see an example from her book, using the use case of an ATM, below.
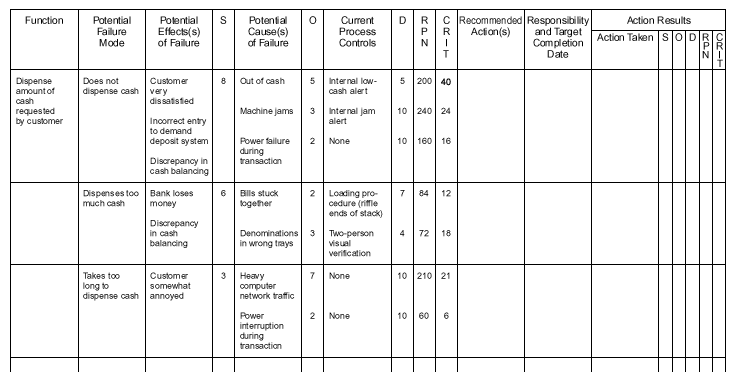
The first step when carrying out your analysis is to determine the scope of what you’re assessing. Is it a single process, a larger department-wide workflow, or a product or service?
The example given above is looking at how an ATM provides money to a user. The first step is to break it down into a series of functions. You can then tackle each function at a time and work through the process. The process flows from left to right along the columns in an easy to follow way. Each potential effect of failure is listed and then given a score in the column next to it.
The S stands for severity and is scored on a 1-10 scale with 10 being the most catastrophic. You then evaluate the cause of the problem and provide each cause with a frequency or occurrence rating: O. Following this, you evaluate the controls in place to stop these problems and assign a detection score (D) to measure how easy it is to detect whether these controls are working. This detection score is based upon the ability for the control to detect the cause of the problem after the cause has occurred, but before the customer has experienced the problem.
These out-of-ten scores are then used to calculate the Risk Priority Number by simply multiplying them all together: S x O x D.
The criticality score in the next column, listed here as CRIT, is calculated by multiplying severity and occurrence.
The Risk Priority Number and the criticality score should then be used to determine the order in which you carry out your process review. This is particularly important if the process is already live so that you can minimize risk as efficiently as possible.
We’ve included a Process Street template below which you can run as a checklist every time you conduct a Failure Mode and Effect Analysis.
If you want a quick guide to using Process Street to guide your processes, watch this short video:
The three key points to remember when using FMEA:
- Make sure all key stakeholders are involved in the process. This kind of process review requires all the expertise of your team to make it effective. Even if you’re a large company with a dedicated process team, the employees working directly on the project – the ATM in the example – will have a better understanding of how the system works and fits together. They may also have a better idea of what solutions can be found to tackle problems as they arise.
- Understand the scope of the FMEA. You can’t run this process on an entire business – there’s just too much data to play with. When performing an analysis, you need to dig deep into a particular process. Be specific. Define what the analysis will look at, and what it won’t.
- For the last time, document your processes. If something goes wrong in future, you will greatly appreciate the actions of your past self if you can go back to review the documentation from the previous analysis. Moreover, if you are a company which has to adhere to set standard operating procedures or regulations, your FMEA will demonstrate your commitment to meeting those targets. You can use the Process Street template above to document how you approached the process, and your analysis and recommendations can be recorded separately in line with the recommended grid system.
What happened to British Airways?

On Saturday May 27th all power went down in one of British Airways key data centers. This problem wasn’t fixed, and operations weren’t restored, until some point the following day, Sunday 28th.
Approximately 800 flights are thought to have been canceled with estimates of around 75,000 travelers affected in some way. The total cost for British Airways is likely to come in at over £50m, with some extremely pessimistic persons estimating it could go as high as £100m.
This is a huge dent on customer trust in British Airways and a very large bill to foot. On Saturday 24th of June, the Guardian was reporting that many travelers still hadn’t been reimbursed for their losses, with BA and insurers both refusing to pay up. British Airways paid one particular family the refund for the flight of £350, but the family claim this has only gone some way to covering their losses with a further £700 they won’t see again.
British Airways made a statement on this individual case when the Guardian approached them for comment:
“We understand how frustrating it was for our customers to have their holidays disrupted last month, so we are pleased that within four days we were able to refund the full cost of the Warren family’s flights and pay compensation they were due. Thousands of families have already received their payments, and we have brought in extra staff to help process applications as quickly as we can.”
There are many cost related effects we can see from the information available, but the financial ramifications of brand damage are much harder to measure. Not everyone is worried, mind. In the last year, Delta Air Lines, Lufthansa, and Air France have all experienced similar outages and significant brand damage doesn’t seem to have occurred.
Willie Walsh, CEO of International Airlines Group, the parent company of British Airways, made a statement in relation to potential brand damage:
We will work to recover our position. British Airways is incredibility resilient. It’s a powerful brand. I’m not going to deny that this is something that has been damaging to the brand, but it hasn’t destroyed it in any way
Nonetheless, BA has suffered some significant losses and had to hire many emergency staff. We know this much to be true.
Why did it happen?
The details of the case are not wholly out in the open. It’s likely that we won’t know exactly what went wrong unless a report is published in the months to come.
Initially, the incident was reported as resulting from a power surge, which suggested an unexpected freak event. However, a few days after the incident an official statement was released informing us of the real cause.
An early statement shed more light on the situation:
There was a loss of power to the UK data centre which was compounded by the uncontrolled return of power which caused a power surge taking out our IT systems. So we know what happened, we just need to find out why,” the airline said in a statement.
Yet, a report from the Times which had access to an internal email revealed a little more detail:
According to The Times, a power supply unit at the centre of the outage was in perfect working order and was deliberately shut down which triggered the disturbance. The paper reported that an investigation of the episode will therefore likely focus on human error.
According to The Times, the incident likely concerned a so-called uninterruptable power supply, or UPS, which is designed to deliver a smooth flow of power from the main with a fall-back to a battery-powered back-up and a diesel generator.
When Walsh made his statement, he appeared to confirm these reports and also provide us with further information:
What caused the damage was that the power was restored in an uncontrolled fashion
He went on to say that the massive surge of power from the Uninterruptable Power Supply (UPS) caused physical damage to British Airways hardware, which was the root cause of the data center being shut down for such a long period of time.
Ultimately, this came down to human error. A contractor disconnected the UPS and then – presumably in panic – reconnected it in an irresponsible way; failing to follow the correct procedures.
This crisis is a process failure. Clear as day.
But why did the process fail? In the media, there has been much discussion about outsourcing. The Daily Mail reported that the engineer in question was employed by CRBE Global Workplace Solutions. While the GMB union made a similar point, as reported by the Financial Times, that British Airways had cut hundreds of IT staff in Britain in 2016 to outsource their work to India.
British Airways responded to these claims:
We would never compromise the integrity and security of our IT systems. IT services are now provided globally by a range of suppliers and this is very common practice across all industries.
Which is a fair point. It has become fairly standard across many industries to have multiple bases across the globe. Whether outsourcing is part of the problem or not seems somewhat redundant in understanding the incident and how to prevent it, even if it’s an important discussion in other ways.
This was a process failure. Looking at the name of the Uninterruptable Power Supply (uninterruptable), we can assume some process wasn’t properly implemented.
How can FMEA help us prevent this happening again?
 Presumably, there was an instruction not to interrupt the uninterruptable power supply. I don’t know this for sure, but I will gladly bet on it.
Presumably, there was an instruction not to interrupt the uninterruptable power supply. I don’t know this for sure, but I will gladly bet on it.
So, I think it is reasonable for us to presume there was a process of some description in place.
Was the problem that the process wasn’t being followed? In which case, I recommend British Airways read up on process adherence and create an account with Process Street for future.
If, on the other hand, the problem was with a lack of adequate controls, then performing a Failure Mode and Effects Analysis is the correct way forward.
Perhaps British Airways should conduct more than one FMEA? If this failure was caused by the contractor, as the Daily Mail reported, then one FMEA should presumably cover the process for onboarding contractors to work within the company’s systems.
Another FMEA could look at the security processes in place surrounding the UPS. Why was one contractor even able to disconnect this crucial supply? Where was the trained supervision?
A further FMEA could be conducted to look at the specific task the contractor was performing. What was the process being followed? Had this process been documented in advance and then reviewed by British Airways staff?
Without wanting to pretend I know better than British Airways – because mistakes always happen – it seems that the effective review and improvement of just one of these processes could have resulted in controls being put in place which may have prevented this whole sorry affair from occurring.
After all, the severity rating for this kind of catastrophe would be very high and likely to show up as a relatively top priority failure mode. It would score low on occurrence rating, but probably high on detection. If we had a S of 9, an O of 2, and a D of 8, the RPN would be 144. This would have raised red flags immediately even if the criticality score had been lower.
Moreover, GMB claimed that hundreds of IT staff were let go only last year. If you’re changing so many employees, this would seem large enough of a change to constitute the need for an FMEA, as per our recommendations above. Had British Airways followed the prescribed process management techniques, they could have put controls in place last year to prevent this costly incident.
The price of not performing effective reviews and not putting well-mapped controls in place is probably going to be much greater than any of the savings they made through their restructuring and outsourcing.
British Airways: The World’s Favourite Airline; somewhat fitting that they’ve dropped this tagline…
For more quality management templates, check out:
Am I being too harsh on British Airlines? Would Failure Mode and Effects Analysis have helped them? Have you used FMEA in your business? Let me know in the comments below!