
 Processes are all the rage right now, and we’re very pleased to be leading the charge in making processes agile and actionable for organizations of all shapes and sizes.
Processes are all the rage right now, and we’re very pleased to be leading the charge in making processes agile and actionable for organizations of all shapes and sizes.
We’ve written countless pieces about creating a process, writing standard operating procedures, or building business systems.
But sometimes we’re guilty of assuming that having a process automatically makes something organized. It doesn’t.
If you’re a solopreneur or working in a startup, managing processes is fairly easy. You have a limited number and you can easily scroll through to find the one you need when you need it.
But what about large organizations? Companies where people on different teams are in different countries? Businesses where different departments speak and operate in different languages?
How can we manage processes on such a large scale, and what does that tell us about managing processes for small businesses looking to scale?
This is where a process library comes in.
In this Process Street article, we’ll look at:
- What is a process library?
- Why you should build a process library for your business
- Determine your information architecture before building your library
- How you can build a process library in Process Street
- Harnessing the power of Process Street’s templates!
Or, if you’ve just come for the templates, grab them below:
Let’s get started!
What is a process library?
A process library is a document management system where you store a detailed breakdown of all your organization’s workflows. This could be a collection of business processes or standard operating procedures, depending on how you organize your business.
In the past, a process library might have been a series of large files where processes and procedures were documented and stored in case they were needed. Some companies still operate like this today.
However, with the rise of business process management, many more businesses have sought to make internal processes more actionable. This has led to a range of BPM software allowing businesses to store processes digitally.
The problem facing us
Though businesses have taken a step forward from their old process libraries which existed as dusty records, they often lack a clear and coherent organization of these newly digitized processes.
This makes processes harder to find, leads to wasted effort in duplicating processes, and reduces overall process adherence.
That’s why in this article, we’ll be looking at how you can create a modern and dynamic process library for your organization, no matter how large and complex it might be.
Why you should build a process library for your business

In our case study of one of our long-time users iQ Food Co COO Arthur Bekerman described his wishes to build a process library.
“The ultimate goal is that every single process we have is documented and either a checklist scenario would be used, or as a reference library.”
The idea of a grand process library to rival the great library of Alexandria is a great addition to your business. Least of all because the library of Alexandria was burned to the ground and a huge sum of human knowledge was lost.
With Process Street, you can store your process library in the cloud and not suffer the fate of Hypatia – though, we can’t actually protect against sharpened seashells. Bit of an insensitive example in hindsight.
Having a strong and effective process library unleashes the powers of these processes themselves.
It makes processes easier to find and follow, while also creating a culture of process improvement if structured well.
Moreover, having the normal practice of building out a process library creates a culture of documentation where recording and improving processes are normalized. This is great in case a staff member leaves, for example, so that you still retain much of their expertise. It’s also incredibly useful for knowledge spill; if I want to understand how our sales team operates on a day to day level, I can just look at their processes. Knowledge can shift more easily around your business when it is easy to find and well cataloged.
Lastly, if you ever want to sell that business, your process library is your business; it makes a purchase safer and more reliable for the new owners coming in. Just something to think about.
Determine your information architecture before building your library
Information architecture is about determining the structural design of an environment which holds knowledge. Every website you go on has some kind of information architecture defined and in place. You can often see this through the site map, though you will likely interact with it via the menus.
Building solid information architecture will likely involve understanding what information, knowledge, or content you have and then grouping or categorizing that content in ways that make sense.
If I want to buy a television from an online store, I might first have to navigate to electronics, then televisions, and then I can choose how I want to further break down my search; by brand, by price, or by size, for example.
The information architecture defines how content is stored on a site and how a visitor could find it.
Information architecture actually has a wide range of definitions depending on who is referring to it and what context it is in, so instead we can look at a few examples.
Libraries in America often categorize by subject

There is a whole range of different systems which libraries use to order and catalog the books and other materials which they store.
One of the most common is the Dewey Decimal system. This system is based around cataloging materials by subject. It was first published in the United States by Melvil Dewey in 1876 and uses numbers to denote main classes, adding decimals where subclasses are needed. The classification system is used in 200,000 libraries in at least 135 countries, and you’ve probably used it before.
Let’s give an example of how this might work.
- 100: Business
- 110: Business administration
- 114: Organizational theory
- 114.5: Business process management
- 114.57: Business process optimization
The Dewey system defines 10 classes. These are the top level categories which everything else falls into. Business is not actually one of the top classes in the Dewey system, but it’s unlikely you’ll transplant the Dewey system as-is into your business.
The Dewey system as it stands is like a very complex tagging system. It helps you find related content around one specific piece of content.
Wikipedia shows that being digital can broaden your categorization

Wikipedia is the great online encyclopedia and puts a whole world of knowledge plus its sources at our fingertips.
But how is Wikipedia structured? According to Noreen Whysel writing for the American Society for Information Science and Technology:
Whysel was part of the group which proposed the WikiProject Information Architecture; an attempt to improve the overall information architecture of the site from the top tier categories down to the content of each page; making it easier to use, navigate, and trust.
Wikipedia, probably partly down to its open-edit nature, has a wide variety of ways it can be seen to be categorized. If you go onto the Wikipedia Contents page, you’ll see this in action.
Wikipedia is initially set out by language, then a selection of primary classes that contains both types of pages and broad subject areas. These classes each have large numbers of subclasses and subsubclasses going down and down.
However, you can also browse Wikipedia using other categorization systems including the Dewey Decimal – a complete list, but incomplete in terms of links, can be found here.
Additionally, you can browse Wikipedia the way most users do: search. In fact, the first thing Wikipedia recommends a user to do on the contents page is to use the search tool.
“There are two ways to look things up in Wikipedia: by searching or by browsing.”
So, perhaps Wikipedia teaches us that it is most effective to utilize a range of categorization and discovery methods, while also informing us that the most user-friendly approach is a search tool?
Process standardization vs process harmonization
If you’re a small business, you’re in a great position to have full process standardization across the board.
If you run a shop, you don’t need five different documented ways to cash up at the end of a shift. If you run two shops, it’s still easy to make sure both of those shops use the same methods.
The problem comes when we reach a point where you have 1,000 shops in different countries following different laws selling different products. Sure, you may still be able to standardize the cashing up process, but now you need to provide it in different languages. Plus, other processes in the stores might have to be subtly different too.
This brings us to a discussion around the relationship between process standardization and process harmonization.
Process standardization is about making one process for one task and keeping it the same wherever it is applied. Process harmonization is about setting a standardized core of a process but allowing subtle changes to certain elements to fit the specific needs of the process user in that scenario.
You can read more about the relationship of these two terms in the 2005 paper by Albrecht Richen and Ansgar Steinhorst, Standardization or Harmonization? You need Both.
A more recent study on the matter by McKinsey, Getting Ruthless With Your Processes, provides us with some key insights.
Of the 300 top executives included in the study, 85% believed that processes “help them share knowledge across divisions and regions”, with the takeaway being that standardized processes improve performance.
But the study also demonstrated that the vast majority of companies are also bad at managing their processes. One participant revealed that their company has 30 separate processes for the act of folding a seat on an oil rig.
The overall point for us from the McKinsey study is that companies should strive to achieve process standardization while also leaving space for harmonization where necessary.
McKinsey pulls out 3 challenges businesses face:
- Too many processes, too little value – Many companies are “reinventing the wheel”; wasting time creating processes that already exist in the company in a different department. These companies do not have enough standardization.
- Over-standardizing processes – Other companies are standardizing their processes to the point where it makes them ineffective. There needs to be a level of harmonization allowed within business processes to maximize their performance.
- Resistance to changing processes – This comes down to an observation by McKinsey of a cultural challenge within businesses. You need to give employees space to attempt to improve processes, even though your aim is standardization.
McKinsey then presents 3 approaches businesses should use:
- Catalog and prioritize your global processes – McKinsey puts great emphasis on the importance of a process library for the effectiveness of any standardization efforts. Staff should be able to draw on the expertise of the company while doing their work.
- Optimize your processes – If this means process harmonization, then go for it. But maybe it means that process harmonization can be a useful way to iterate and test a process to improve the central standard one? How you approach it practically will depend on your company. Optimized processes are a key goal either way.
- Implement change from the top – Create a culture beneficial to business process management. You could create a process-oriented team which serves to bring related staff from different regions or divisions together on a monthly or quarterly basis to discuss the standard vs harmonized processes within their respective teams. Keep monitoring process management within the company and help facilitate both standardization and improvement.
So, all this tells us two things:
- We need a process library and we need that library to facilitate standardization.
- We need to create space within that library structure for variance and iterations of process models.
How you can build a process library in Process Street
What we’re going to do here is take an overly complex use case and demonstrate a way you could use Process Street’s features to achieve a process library that adheres to best practice, drawing upon the lessons from the above section.
We’re going to imagine a generic multi-national company which has operations in a host of different regions around the world. This means it needs to facilitate multiple languages, communication of core processes, and variance of process models where necessary.
Let’s see how we can practically do this.
Use folders to categorize your processes
The first step is to understand that all process templates you create in Process Street can be stored in folders. These folders can then have sub folders.
What I’m proposing here for our hypothetical multinational is to have a dominant folder at the top of the tree. I’m calling it Core Processes. Using the permissions feature we’ll outline later, 99% of staff will never have to interact with this folder directly, only certain contents of the folder which they’re given access to.
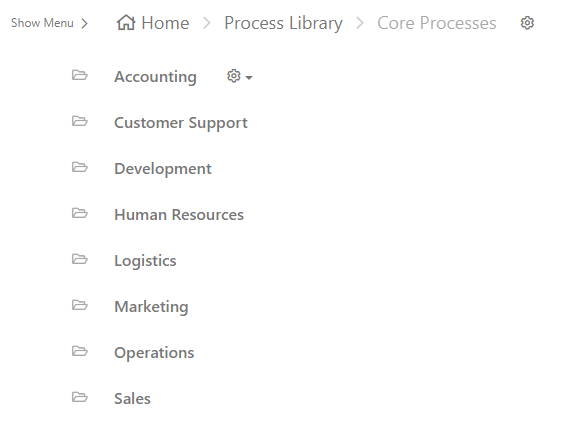
 Within this folder, the subfolders and sub-subfolders exist in a way that mirrors the company structure; broken down by department.
Within this folder, the subfolders and sub-subfolders exist in a way that mirrors the company structure; broken down by department.
 I would also have another folder at the top of the tree where locally specific versions of processes can also exist. The subfolder structure inside this folder would mirror the Core Processes, other than an additional layer at the top for either regions or languages depending on the company structure.
I would also have another folder at the top of the tree where locally specific versions of processes can also exist. The subfolder structure inside this folder would mirror the Core Processes, other than an additional layer at the top for either regions or languages depending on the company structure.
These folders would contain potentially other language variations of the relevant core processes, or contain iterated versions of the core processes. These iterated versions could be used, measured, and evaluated to gauge performance and could then be proposed for integration into the Core Processes section of the library.
To move a template between folders only requires you to click into the template’s options, click More, and select Move this template. The task is incredibly easy, and this would allow you to test process model variations before moving into the master list. However, for small changes to process models, you could simply edit the original version in the Core Processes and it would auto-update for every new checklist ran. No need for code or waiting.
You could have folders all the way down to specific sub-teams or working groups within the organization.
Use tags to make related processes easy to find
If you have a huge number of processes, then you may want to create an effective tagging system that helps you navigate through them all or even search-related processes.
This is where you could reapply the Dewey Decimal system described in the sections above. You can tweak the system to your needs.
If you created a process for staff to use when building new processes, then one step could be to determine the number tagging for the template they’re building. You could include a run link into this task and that would automatically open up a guide to your internal Dewey system – which might look something like the image below.
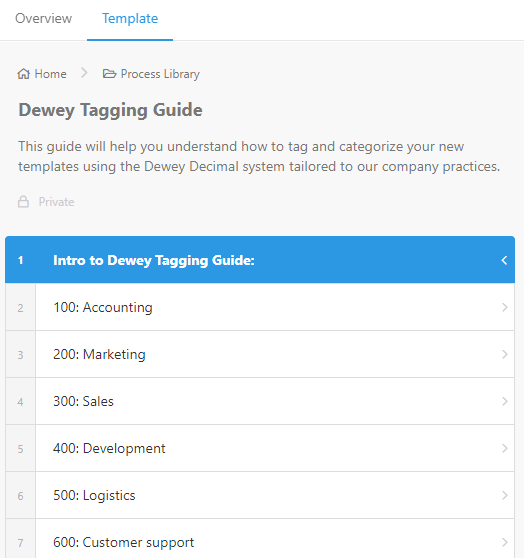 This could provide a growing and flexible taxonomy of all available processes. If it’s a system big enough for libraries then it should be big enough for your business.
This could provide a growing and flexible taxonomy of all available processes. If it’s a system big enough for libraries then it should be big enough for your business.
The process I run to prepare this post for publication might be called a Blog Prepublish Checklist, but in this tagging system, it would a 212.3 Blog Prepublish Checklist, for example.
This means that if I wanted to see other blog-related checklists I could search in the Process Street search bar: 212.
If I wanted to see other content marketing related processes, I could search 210.
Additionally, all tags with checklists you have access to will show up on the left-hand side of your home screen for easy scrollable access; providing multiple ways to find the processes you need and to explore related processes.
Assign user permissions to control access
I know this doesn’t sound like a fancy feature. But, I think this could be the key to making a gigantic process library actually usable for the day to day worker.
Our CEO, Vinay, said to me while discussing the concept of process libraries as actionable tools:
“The best information architecture for this is showing someone exactly what they need to see and nothing else.”
And I agree with him. I don’t want my screen which I interact with in order to follow processes to be flooded with processes from other departments. I want what I need and I want it in front of me.
From a business perspective, as well, there are a number of reasons you don’t want an open access Wikipedia/library model. You might have proprietary information, security procedures, or accounting procedures designed to combat fraud. You don’t necessarily want all of this information available and visible to everyone.
With our user permission functionalities, you can assign users to particular folders. They will see the contents of the folders they’re assigned and nothing else.
You can also assign people to Groups and then control access via the group or groups someone is a member of.
 To continue with the example from the Folders section above: If the large company hires a writer for its content marketing, but they’re in Spain, that worker might be given access to the content marketing folder in Core Processes and to the content marketing folder specific to their region/language in Local Processes.
To continue with the example from the Folders section above: If the large company hires a writer for its content marketing, but they’re in Spain, that worker might be given access to the content marketing folder in Core Processes and to the content marketing folder specific to their region/language in Local Processes.
The one in Local Processes can have some processes specific to their team, and could also act as a sandbox if they want to experiment with building new processes for new tasks.
When they log into Process Street, all they will see are those two folders and whatever those folders contain.
This makes it super simple for them to interact with their processes, and not have to worry about other elements.
Of course, you’re in control of your permissions. You could have every process visible to the entire company if you wanted. Only you as an admin would ever have to worry about seeing how the information architecture is constructed within the platform.
By managing user permissions you can streamline the experience of your workers.
Harnessing the power of Process Street’s templates!
By this point, I’m sure you’ve realized how effective having a process library inside Proces Street is.
And to help you with having a robust, solid process library – and great processes to boot – I’ve got several templates for you…
Process Library Checklist
This Process Library Checklist will guide you through the steps of creating a process library from scratch.
Here’s how it works.
First, you’ll answer a dropdown and confirm if it’s your first time running the process or not. This is where conditional logic comes into play.
If it is your first time running it, you’ll go through the process of ensuring all processes are documented, figuring out the process library’s architecture, creating the library itself, and then optimizing it via a tagging system and setting user permissions.
If it is not your first time, you’ll go through steps that help you review your already-established process library. It’s recommended that the process library is reviewed every 3 months.
What’s more is that it’s superpowered by Process Street’s workflow automation features such as approvals, role assignments, and stop tasks!
Click here to get the Process Library Checklist!
The Process for Optimizing a Process
The processes inside your process library need to be up-to-date and optimized.
Why?
Because, with optimized processes, you can save time, money, and labor!
However, it’s often the case that organizations don’t know where to begin with process optimization.
Luckily, this Process for Optimizing a Process will guide you through every step of the way. It’s based on the DMAIC structure, which Thom James Carter goes into more detail on in his post Business Process Optimization: How to Improve Workflows Like a Pro (Free Templates!).
Interested in trying it yourself?
Click here to get the Process for Optimizing a Process!
By signing up for free, adding these processes to your account, and then following them, your process library will be outstanding.
Check out how companies like Mainline Autobody are creating and using their process libraries below.
What kind of process libraries have you used in the past? Have you tried to effectively digitize them before? Let us know your experiences in the comments below!